Just over eight years ago Chris Anderson of Wired announced with typical Silicon Valley humility that big data had made the scientific method obsolete. Seemingly innocent of any training in science, Anderson explained that correlation is enough; we can stop looking for models.
Anderson came to mind as I wrote my previous post on Richard Feynman’s philosophy of science and his strong preference for the criterion of explanatory power over the criterion of predictive success in theory choice. By Anderson’s lights, theory isn’t needed at all for inference. Anderson didn’t see his atheoretical approach as non-scientific; he saw it as science without theory.
Anderson wrote:
“…the big target here isn’t advertising, though. It’s science. The scientific method is built around testable hypotheses. These models, for the most part, are systems visualized in the minds of scientists. The models are then tested, and experiments confirm or falsify theoretical models of how the world works. This is the way science has worked for hundreds of years… There is now a better way. Petabytes allow us to say: ‘Correlation is enough.’… Correlation supersedes causation, and science can advance even without coherent models, unified theories, or really any mechanistic explanation at all.”
Anderson wrote that at the dawn of the big data era – now known as machine learning. Most interesting to me, he said not only is it unnecessary to seek causation from correlation, but correlation supersedes causation. Would David Hume, causation’s great foe, have embraced this claim? I somehow think not. Call it irrational data exuberance. Or driving while looking only into the rear view mirror. Extrapolation can come in handy; but it rarely catches black swans.
Philosophers of science concern themselves with the concept of under-determination of theory by data. More than one theory can fit any set of data. Two empirically equivalent theories can be logically incompatible, as Feynman explains in the video clip. But if we remove theory from the picture, and predict straight from the data, we face an equivalent dilemma we might call under-determination of rules by data. Economic forecasters and stock analysts have large collections of rules they test against data sets to pick a best fit on any given market day. Finding a rule that matches the latest historical data is often called fitting the rule on the data. There is no notion of causation, just correlation. As Nassim Nicholas Taleb describes in his writings, this approach can make you look really smart for a time. Then things change, for no apparent reason, because the rule contains no mechanism and no explanation, just like Anderson said.
In Bobby Henderson’s famous Pastafarian Open Letter to Kansas School Board, he noted the strong inverse correlation between global average temperature and the number of seafaring pirates over the last 200 years. The conclusion is obvious; we need more pirates.
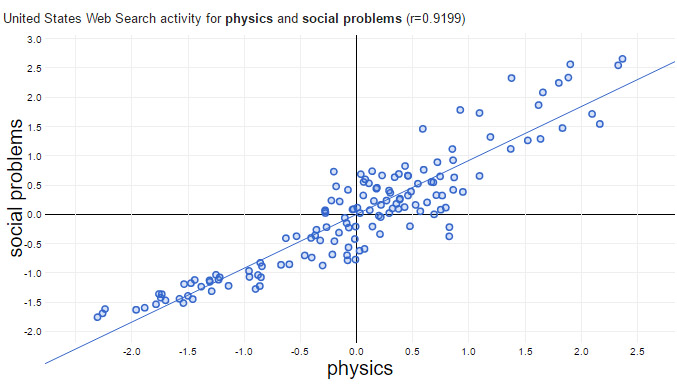
My recent correlation-only research finds positive correlation (r = 0.92) between Google searches on “physics” an “social problems.” It’s just too hard to resist seeking an explanation. And, as positivist philosopher Carl Hempel stressed, explanation is in bed with causality; so I crave causality too. So which is it? Does a user’s interest in physics cause interest in social problems or the other way around? Given a correlation, most of us are hard-coded to try to explain it – does a cause b, does b cause a, does hidden variable c cause both, or is it a mere coincidence?
Big data is a tremendous opportunity for theory-building; it need not supersede explanation and causation. As Sean Carroll paraphrased Kant in The Big Picture:
“Theory without data is blind. Data without theory is lame.”
— — —
[edit 7/28: a lighter continuation of this topic here]
.
Happy is he who gets to know the causes of things – Virgil

#1 by Anonymous on July 25, 2016 - 10:12 am
“Seemingly innocent of any training in science …” Priceless.