For most of us, there is a large gap between what we know and what we think we know. We hold a level of confidence about our factual knowledge and predictions that doesn’t match our abilities. Since our personal decisions are really predictions about the future based on our available present knowledge, it makes sense to work toward adjusting our confidence to match our skill.
Last year I measured the knowledge-confidence gap of 3500 participants in a trivia game with a twist. For each True/False trivia question the respondents specified their level of confidence (between 50 and 100% inclusive) with each answer. The questions, presented in banks of 10, covered many topics and ranged from easy (American stop signs have 8 sides) to expert (Stockholm is further west than Vienna).
I ran this experiment on a website and mobile app using 1500 True/False questions, about half of which belonged to specific categories including music, art, current events, World War II, sports, movies and science. Visitors could choose between the category “Various” or from a specific category. I asked for personal information such as age, gender current profession, title, and education. About 20% of site visitors gave most of that information. 30% provided their professions.
Participants were told that the point of the game was not to get the questions right but to have an appropriate level of confidence. For example, if a your average confidence value is 75%, 75% of their your answers should be correct. If your confidence and accuracy match, you are said to be calibrated. Otherwise you are either overconfident or underconfident. Overconfidence – sometime extreme – is more common, though a small percentage are significantly underconfident.
Overconfidence in group decisions is particularly troubling. Groupthink – collective overconfidence and rationalized cohesiveness – is a well known example. A more common, more subtle, and often more dangerous case exists when social effects and the perceived superiority of judgment of a single overconfident participant can leads to unconscious suppression of valid input from a majority of team members. The latter, for example, explains the Challenger launch decision for more than classic groupthink does, though groupthink is often cited as the cause.
I designed the trivia quiz system so that each group of ten questions under the Various label included one that dealt with a subject about which people are particularly passionate – environmental or social justice issues. I got this idea from Hans Rosling’s book, Factfulness. As expected, respondents were both overwhelmingly wrong and acutely overconfident about facts tied to emotional issues, e.g., net change in Amazon rainforest area in last five years.
I encouraged people to use take a few passes through the Various category before moving on to the specialty categories. Assuming that the first specialty categories that respondents chose was their favorite, I found them to be generally more overconfident about topics they presumable knew best. For example, those that first selected Music and then Art showed both higher resolution (correctness) and higher overconfidence in Music than they did in Art.
Mean overconfidence for all first-chosen specialties was 12%. Mean overconfidence for second-chosen categories was 9%. One interpretation is that people are more overconfident about that which they know best. Respondents’ overconfidence decreased progressively as they answered more questions. In that sense the system served as confidence calibration training. Relative overconfidence in the first specialty category chosen was present even when the effect of improved calibration was screened off, however.
For the first 10 questions, mean overconfidence in the Various category was 16% (16% for males, 14% for females). Mean overconfidence for the nine question in each group excepting the “passion” question was 13%.
Overconfidence seemed to be constant across professions, but increased about 1.5% with each level of college education. PhDs are 4.2% more overconfident than high school grads. I’ll leave that to sociologists of education to interpret. A notable exception was a group of analysts from a research lab who were all within a point or two of perfect calibration even on their first 10 questions. Men were slightly more overconfident than women. Underconfidence (more than 5% underconfident) was absent in men and present in 6% of the small group identifying as women (98 total).
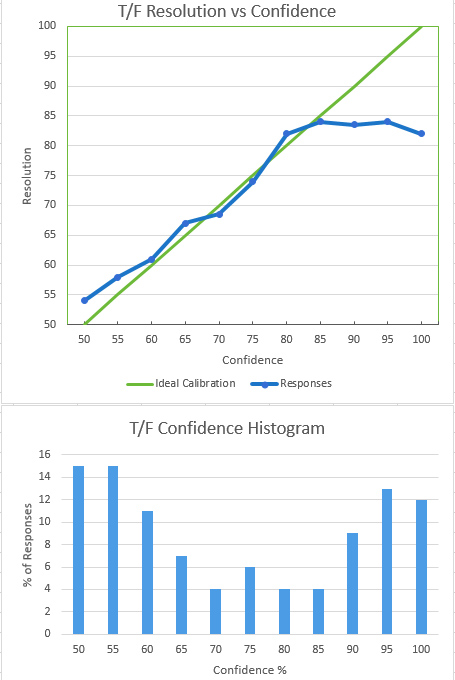
The nature of overconfidence is seen in the plot of resolution (response correctness) vs. confidence. Our confidence roughly matches our accuracy up to the point where confidence is moderately high, around 85%. After this, increased confidence occurs with no increase in accuracy. At at 100% confidence level, respondents were, on average, less correct than they were at 95% confidence. Much of that effect stemmed from the one “trick” question in each group of 10; people tend to be confident but wrong about hot topics with high media coverage.
The distribution of confidence values expressed by participants was nominally bimodal. People expressed very high or very low confidence about the accuracy of their answers. The slight bump in confidence at 75% is likely an artifact of the test methodology. The default value of the confidence slider (website user interface element) was 75%. On clicking the Submit button, users were warned if most of their responses specified the default value, but an acquiescence effect appears to have present anyway. In Superforecasters Philip Tetlock observed that many people seem to have a “three settings” (yes, no, maybe) mindset about matters of probability. That could also explain the slight peak at 75%.
I’ve been using a similar approach to confidence calibration in group decision settings for the past three decades. I learned it from a DoD publication by Sarah Lichtenstein and Baruch Fischhoff while working on the Midgetman Small Intercontinental Ballistic Missile program in the mid 1980s. Doug Hubbard teaches a similar approach in his book The Failure of Risk Management. In my experience with diverse groups contributing to risk analysis, where group decisions about likelihood of uncertain events are needed, an hour of training using similar tools yields impressive improvements in calibration as measured above.

#1 by Matthew Squair on April 22, 2021 - 3:37 pm
That de correlation at high confidence may explain why experts can be stonkingky wrong on a regular basis. Lack of epistemic humility. 🙂
#2 by Bill Storage on April 22, 2021 - 7:19 pm
That and possibly Kahneman’s “illusory skill” thing.
A multi-decade study by Philip Tetlock, tracking 80,000 expert predictions, concluded that the experts had performed slightly worse than dart throwing chimpanzees (i.e., random chance) in their predictions. While those with some knowledge did better than those with none, those with the highest levels of knowledge in a subject made worse predictions about that subject. Tetlock wrote “we reach the point of diminishing marginal predictive returns for knowledge disconcertingly quickly” in his 2005 Expert Political Judgment: How Good Is It?.
A similar study by CXO Advisory Group between 2005 and 2012 covered 6500 market forecasts finding an overall accuracy of 47.4 percent. Again, worse than random. Tetlock observes that expert pundits are massively overconfident, even after their predictions “prove stone-cold wrong.” Levitt and Dubner (Freakonomics) call this a “lethal combination – cocky plus wrong – especially when a more prudent option exists: simply admit that the future is far less knowable than you think.”
#3 by Rick Brakeman on April 23, 2021 - 5:19 pm
It’s hard to believe that the health bureau experts calibrate their estimating process for COVID.
Cocky + Wrong + Sinister = Lethal Combo ^ 10.
#4 by Ken Pascoe on April 27, 2021 - 11:34 am
Will you publish this in a peer-reviewed journal? Experts need to learn not to be so cocky, but they will dismiss you if you aren’t peer reviewed. For better or worse, they assume the peers doing the reviewing are experts.