Archive for May, 2025
Dialogue Concerning a Cup of Cooked Collards
Posted by Bill Storage in Fiction, History of Science on May 27, 2025
in which the estimable Signora Sagreda, guided by the lucid reasoning of Salviatus and the amiable perplexities of Simplicius, doth inquire into the nature of culinary measurement, and wherein is revealed, by turns comic and calamitous, the logical dilemma and profound absurdity of quantifying cooked collards by volume, exposing thereby the nutritional fallacies, atomic impossibilities, and epistemic mischiefs that attend such a practice, whilst invoking with reverence the spectral wisdom of Galileo Galilei.
Scene: A modest parlor, with a view into a well-appointed kitchen. A pot of collards simmers.
Sagreda: Good sirs, I am in possession of a recipe, inherited from a venerable aunt, which instructs me to add one cup of cooked collards to the dish. Yet I find myself arrested by perplexity. How, I ask, can one trust such a measure, given the capricious nature of leaves once cooked?
Salviatus: Ah, Signora, thou hast struck upon a question of more gravity than may at first appear. In that innocent-seeming phrase lies the germ of chaos, the undoing of proportion, and the betrayal of consistency.
Simplicius: But surely, Salviatus, a cup is a cup! Whether one deals with molasses, barley, or leaves of collard! The vessel measures equal, does it not?

Salviatus: Ah, dear Simplicius, how quaint thy faith in vessels. Permit me to elaborate with the fullness this foolishness begs. A cup, as used here, is a measure of volume, not mass. Yet collards, when cooked, submit themselves to the will of the physics most violently. One might say that a plenty of raw collards, verdant and voluminous, upon the fire becomes but a soggy testament to entropy.
Sagreda: And yet if I, with ladle in hand, press them lightly, I may fill a cup with tender grace. But if I should tamp them down, as a banker tamps tobacco, I might squeeze thrice more into the same vessel.
Salviatus: Just so! And here lies its absurdity. The recipe calls for a cup, as though the collards were flour, or water, or some polite ingredient that hold the law of uniformity. But collards — and forgive my speaking plainly — are rogues. One cook’s gentle heap is another’s aggressive compression. Thus, a recipe using such a measure becomes not a method, but a riddle, a culinary Sphinx.
Simplicius: But might not tradition account for this? For is it not the case that housewives and cooks of yore prepared these dishes with their senses and not with scales?
Salviatus: A fair point, though flawed in its application. While the tongue and eye may suffice for the seasoned cook, the written recipe aspires to universality. It must serve the neophyte, the scholar, the gentleman abroad who seeks to replicate his mother’s collard pie with exactitude. And for these noble aims, only the scale may speak truth. Grams! Ounces! Units immutable, not subject to whim or squish!
Sagreda: You speak as though the collards, once cooked, engage in a deceit, cloaking their true nature.
Salviatus: Precisely. Cooked collards are like old courtiers — soft, pliable, and accustomed to hiding their substance beneath a veneer of humility. Only by weight can one know their worth. Or, more precisely, by its mass, the measure we know to not affect the rate at which objects fall.
Simplicius: But if all this be so, then is not every cookbook a liar? Is not every recipe suspect?
Salviatus: Not every recipe — only those who trade in volumetric folly where mass would bring enlightenment. The fault lies not in the recipe’s heart, but in its measurement. And this, dear Simplicius, we may yet amend.
Sagreda: Then shall we henceforth mark in our books, “Not a cup, but a weight; not a guess, but a truth“? For a measure of collards, like men, must be judged not by appearance, but by their substance.
Sagreda (reflecting): And yet, gentlemen, if I may permit a musing most unorthodox, does not all this emphasis on precision edge us perilously close to an unyielding, mechanical conception of science? Dare we call it… dogmatic?
Simplicius: Dogmatic? You surprise me, Signora. I thought it only the religion of Bellarmino and Barberini could carry such a charge.
Salviatus: Ha! Then you have not read the scribblings of Herr Paulus Feyerabend, who, proclaims with no small glee — and with more than of a trace of Giordano Bruno — that anything goes in the pursuit of knowledge. He teaches that the science, when constrained by method, becomes no different from myth.
Sagreda: Fascinating! And would this Feyerabend defend, then, the use of “a cup of cooked collards” as a sound epistemic act?
Salviatus: Indeed, he might. He would argue that inexactitude, even vagueness, can have its place. That Sagreda’s venerable aunt, the old wives, the village cooks, with their pinches and handfuls and mysteriously gestured “quanta bastas,” have no less a claim to truth than a chef armed with scales and thermocouples. He might well praise the “cup of cooked collards” as a liberating epistemology, a rejection of culinary tyranny.
Simplicius: Then Feyerabend would have me trust Sagreda’s aunt over the chemist?
Salviatus: Just so — he would, and be half right at least! Feyerabend’s quarrel is not with truth, but with monopoly over its definition. He seeks not the destruction of science, but the dethronement of science enthroned as sacred law. In this spirit, he might say: “Let the collards be measured by weight, or not at all, for the joy of the dish may reside not in precision, but in a dance of taste and memory.”
Sagreda: A heady notion! And perhaps, like a stew, the truth lies in the balance — one must permit both the grammar of measurement and the poetry of intuition. The recipe, then, is both science and art, its ambiguity not a flaw, but sometimes an invitation.
Salviatus: Beautifully said, Signora. Yet let us remember: Feyerabend champions chaos as a remedy for tyranny, not as an end in itself. He might defend the cook who ignores the scale, but not the recipe which claims false precision where none is due. And so, if we declare “a cup of cooked collards,” we ought either to define it, or admit with humility that we have no idea how many leaves is right to each observer.
Simplicius: Then science and the guessing of aunts may coexist — so long as neither pretends to be the other?
Salviatus: Precisely. The scale must not scorn the hunch, nor the cup dethrone the scale. But let us not forget: when preparing a dish to be replicated, mass is our anchor in the storm of leafy deception.
Sagreda (opening her laptop): Ah! Then let us dedicate this dish — to Feyerabend, to Bruno, to my venerable aunt. I will append to her recipe, notations from these reasonings on contradiction and harmony.
Cooked collards are like old courtiers — soft, pliable, and accustomed to hiding their substance beneath a veneer of humility — Salviatus
Sagreda (looking up from her laptop with astonishment): Gentlemen! I have stumbled upon a most curious nutritional claim. This USDA document — penned by government scientist or rogue dietitian — declares with solemn authority that a cup of cooked collards contains 266 grams calcium and a cup raw only 52.
Salviatus (arching an eyebrow): More calcium? From whence, pray, does this mineral bounty emerge? For collards, like men, cannot give what they do not possess.

Simplicius (waving a wooden spoon): It is well known, is it not, that cooking enhances healthfulness? The heat releases the virtues hidden within the leaf, like Barberini stirring the piety of his reluctant congregation!
Salviatus: Simplicius, your faith outpaces your chemistry. Let us dissect this. Calcium, as an element, is not born anew in the pot. It is not conjured by flame nor summoned by steam. It is either present, or it is not.
Simplicius: So how, then, can it be that the cooked collards have more calcium than their raw counterparts — cup for cup?
Sagreda: Surely, again, the explanation is compression. The cooking drives out water, collapses volume, and fills the cup more densely with matter formerly bulked by air and hubris.
Salviatus: Exactly so! A cup of cooked collards is, in truth, the compacted corpse of many cups raw — and with them, their calcium. The mineral content has not changed; only the volume has bowed before heat’s stern hand.
Simplicius: But surely the USDA, a most probable power, must be seen as sovereign on the matter. Is there no means, other than admitting the slackness of their decree, by which we can serve its authority?
Salviatus: Then, Simplicius, let us entertain absurdity. Suppose for a moment — as a thought experiment — that the cooking process does, in fact, create calcium.
By what alchemy? What transmutation?
Let us assume, in a spirit of lunatic (and no measure anachronous) generosity, that the humble collard leaf contains also magnesium — plentiful, impudent magnesium — and that during cooking, it undergoes nuclear transformation. Though they have the same number of valence electrons, to turn magnesium (atomic number 12) into calcium (atomic number 20), we must add 8 protons and a healthy complement of neutrons.
Sagreda: But whence come these subatomic parts? Shall we pluck nucleons from the steam?
Salviatus (solemnly): We must raid the kitchen for protons as a burglar raids a larder. Perhaps the protons are drawn from the salt, or the neutrons from baking powder, or perhaps our microwave is a covert collider, transforming our soup pot into CERN-by-candlelight.
But alas — this would take more energy than a dozen suns, and the vaporizing of the collards in a burst of gamma rays, leaving not calcium-rich greens but a crater and a letter of apology due. But, we know, do we not, that the universe is indifferent to apology; the earth still goes round the sun.
Sagreda: Then let us admit: the calcium remains the same. The difference is illusion — an artifact of measurement, not of matter.
Salviatus: Precisely. And the USDA, like other sovereigns, commits nutritional sophistry — comparing unlike volumes and implying health gained by heat alone, or, still worse, that we hold it true by unquestioned authority.
Let this be our final counsel: whenever the cup is invoked, ask, “Cup of what?” If it be cooked, know that you measure the ghost of raw things past, condensed, wilted, and innocent of transmutation.
The scale must not scorn the hunch, nor the cup dethrone the scale. – Salviatus
Thus ends the matter of the calcium-generating cauldron, in which it hath been demonstrated to the satisfaction of reason and the dismay of the USDA that no transmutation of elements occurs in the course of stewing collards, unless one can posit a kitchen fire worthy of nuclear alchemy; and furthermore, that the measure of leafy matter must be governed not by the capricious vulgarity of volume, but by the steady hand of mass, or else be entrusted to the most excellent judgment of aunts and cooks, whose intuitive faculties may triumph over quantification outright. The universe, for its part, remains intact, and the collards, alas, are overcooked.

Giordano Bruno discusses alchemy with Paul Feyerabend. Campo de’ Fiori, Rome, May 1591.
Galileo’s Dialogue Concerning the Two Chief World Systems is a proto-scientific work presented as a conversation among three characters: Salviati, Sagredo, and Simplicio. It compares the Copernican heliocentric model (Earth revolves around Sun) and the traditional Ptolemaic geocentric model (Earth as center). Salviati represents Galileo’s own views and advocates for the Copernican system, using logic, mathematics, observation, and rhetoric. Sagredo is an intelligent, neutral layman who asks questions and weighs the arguments, representing the open-minded reader. Simplicio, a supporter of Aristotle and the geocentric model held by the church, struggles to defend his views and is portrayed as naive. Through their discussion, Galileo gives evidence for the heliocentric model and critiques the shortcomings of the geocentric, making a strong case for scientific reasoning based on observation rather than tradition and authority. Cardinal Roberto Bellarmino and Maffeo Barberini (Pope Urban VIII) were the central clergy figures in Galileo’s trial. In 1970 Paul Feyerabend argued that modern institutional science resembled the church more than it did Galileo. The Dominican monk, Giordano Bruno, held unorthodox ideas in science and theology. Bellarmino framed the decision leading to his conviction of heresy in 1600. He was burned at the stake in the plaza of Campo de’ Fiori, where I stood not one hour before writing this.

Galileo with collard vendors in Pisa
New Marble Portrait of Augustus
Posted by Bill Storage in History of Art on May 24, 2025



For 23 years Laura Maish and I have been shooting photos of republican and imperial portraits. We’ve accumulated 30,000 photos of ancient marble and bronze heads.
Our latest addition, just photographed this week in Rome, is the below Alcudia-type head of Augustus discovered in 2019 along Via Alessandrina in Rome Mercati di Traiano and recently put on display in the Trajan’s Market museum. This typology, named after a similar portrait found in Alcudia, Spain, dates to 40–38 BCE and depicts Octavian in his early twenties. This type aligns with Augustus’ adoption of the title Divi Filius (Son of the Deified*) following Julius Caesar’s deification. Alcudia-type portraits of Augustus are rare, so this was a significant find.
* This is often incorrectly translated as “Son of the Divine.” Divus (from which Divi comes) refers specifically to a mortal who has been deified after death, not to an eternal or inherently divine being (like a traditional god such as Jupiter). Deus, by contrast, refers to a god or divine being in a more traditional, eternal sense.



This Alcúdia type bust portrays Augustus with a youthful face, featuring a broad forehead, sharp brow, and almond-shaped eyes with thin lids. The facial modeling is restrained, part realistic individualism and part classicizing elements inspired by Greek sculpture, particularly the works like the Doryphoros of Polykleitos. His expression is calm and dignified, reflecting the Augustan ideal of serene authority.
A defining feature is the distinctive arrangement of hair, with thick, comma-shaped locks combed forward, often with a pronounced central “clip” formed by two locks curving to the right and one to the left. The hair over the forehead is voluminous, with some strands undercut for a three-dimensional effect, and it closely follows the skull, contrasting with later types like the Prima Porta, where the hair is more simplified. As with the other Alcúdia-type portraits the rest of the hair is smoother and less detailed compared to later Augustan portraits.
This piece appears to be carved from Parian marble. I could not find any info on it and I’m unskilled in petrography. It is some kind of high-quality, fine-grained, homogeneous lychnite.
Visit this page for photos of many more portraits of Augustus.



Bad Science, Broken Trust: Commentary on Pandemic Failure
Posted by Bill Storage in History of Science on May 20, 2025
In my three previous posts (1, 2, 3) on the Covid-19 response and statistical reasoning, I deliberately sidestepped a deeper, more uncomfortable truth that emerges from such analysis: that ideologically driven academic and institutional experts – credentialed, celebrated, and deeply embedded in systems of authority – played a central role in promoting flawed statistical narratives that served political agendas and personal advancement. Having defended my claims in two previous posts – from the perspective of a historian of science – I now feel I justified in letting it rip. Bad science, bad statistics, and institutional arrogance directly shaped a public health disaster.
What we witnessed was not just error, but hubris weaponized by institutions. Self-serving ideologues – cloaked in the language of science – shaped policies that led, in no small part, to hundreds of thousands of preventable deaths. This was not a failure of data, but of science and integrity, and it demands a historical reckoning.
The Covid-19 pandemic exacted a devastating toll: a 13% global GDP collapse in Q2 2020, and a 12–15% spike in adolescent suicidal ideation, as reported by Nature Human Behaviour (2020) and JAMA Pediatrics (2021). These catastrophic outcomes –economic freefall and a mental health crisis – can’t be blamed on the pathogen. Its lethality was magnified by avoidable policy blunders rooted in statistical incompetence and institutional cowardice. Five years on, the silence from public health authorities is deafening. The opportunity to learn from these failures – and to prevent their repetition – is being squandered before our eyes.
One of the most glaring missteps was the uncritical use of raw case counts to steer public policy – a volatile metric, heavily distorted by shifting testing rates, as The Lancet (2021, cited earlier) highlighted. More robust measures like deaths per capita or infection fatality rates, advocated by Ioannidis (2020), were sidelined, seemingly for facile politics. The result: fear-driven lockdowns based on ephemeral, tangential data. The infamous “6-foot rule,” based on outdated droplet models, continued to dominate public messaging through 2020 and beyond – even though evidence (e.g., BMJ, 2021) solidly pointed to airborne transmission. This refusal to pivot toward reality delayed life-saving ventilation reforms and needlessly prolonged school closures, economic shutdowns, and the cascading psychological harm they inflicted.
At the risk of veering into anecdote, this example should not be lost to history: In 2020, a surfer was arrested off Malibu Beach and charged with violating the state’s stay-at-home order. As if he might catch or transmit Covid – alone, in the open air, on the windswept Pacific. No individual could possibly believe that posed a threat. It takes a society – its institutions, its culture, its politics – to manufacture collective stupidity on that scale.
The consequences of these reasoning failures were grave. And yet, astonishingly, there has been no comprehensive, transparent institutional reckoning. No systematic audits. No revised models. No meaningful reforms from the CDC, WHO, or major national agencies. Instead, we see a retrenchment: the same narratives, the same faces, and the same smug complacency. The refusal to account for aerosol dynamics, mental health trade-offs, or real-time data continues to compromise our preparedness for future crises. This is not just negligence. It is a betrayal of public trust.
If the past is not confronted, it will be repeated. We can’t afford another round of data-blind panic, policy overreach, and avoidable harm. What’s needed now is not just reflection but action: independent audits of pandemic responses, recalibrated risk models that incorporate full-spectrum health and social impacts, and a ruthless commitment to sound use of data over doctrine.
The suffering of 2020–2022 must mean something. If we want resilience next time, we must demand accountability this time. The era of unexamined expert authority must end – not to reject expertise – but to restore it to a foundation of integrity, humility, and empirical rigor.
It’s time to stop forgetting – and start building a public health framework worthy of the public it is supposed to serve.
___ ___ ___
Covid Response – Case Counts and Failures of Statistical Reasoning
Posted by Bill Storage in History of Science on May 19, 2025
In my previous post I defended three claims made in an earlier post about relative successes in statistics and statistical reasoning in the American Covid-19 response. This post gives support for three claims regarding misuse of statistics and poor statistical reasoning during the pandemic.
Misinterpretation of Test Results (4)
Early in the COVID-19 pandemic, many clinicians and media figures misunderstood diagnostic test accuracy, misreading PCR and antigen test results by overlooking pre-test probability. This caused false reassurance or unwarranted alarm, though some experts mitigated errors with Bayesian reasoning. This was precisely the type of mistake highlighted in the Harvard study decades earlier. (4)
Polymerase chain reaction (PCR) tests, while considered the gold standard for detecting SARS-CoV-2, were known to have variable sensitivity (70–90%) depending on factors like sample quality, timing of testing relative to infection, and viral load. False negatives were a significant concern, particularly when clinicians or media interpreted a negative result as definitively ruling out infection without considering pre-test probability (the likelihood of disease based on symptoms, exposure, or prevalence). Similarly, antigen tests, which are less sensitive than PCR, were prone to false negatives, especially in low-prevalence settings or early/late stages of infection.
A 2020 article in Journal of General Internal Medicine noted that physicians often placed undue confidence in test results, minimizing clinical reasoning (e.g., pre-test probability) and deferring to imperfect tests. This was particularly problematic for PCR false negatives, which could lead to a false sense of security about infectivity.
A 2020 Nature Reviews Microbiology article reported that during the early pandemic, the rapid development of diagnostic tests led to implementation challenges, including misinterpretation of results due to insufficient consideration of pre-test probability. This was compounded by the lack of clinical validation for many tests at the time.
Media reports often oversimplified test results, presenting PCR or antigen tests as definitive without discussing limitations like sensitivity, specificity, or the role of pre-test probability. Even medical professionals struggled with Bayesian reasoning, leading to public confusion about test reliability.
Antigen tests, such as lateral flow tests, were less sensitive than PCR (pooled sensitivity of 64.2% in pediatric populations) but highly specific (99.1%). Their performance varied significantly with pre-test probability, yet early in the pandemic, they were sometimes used inappropriately in low-prevalence settings, leading to misinterpretations. In low-prevalence settings (e.g., 1% disease prevalence), a positive antigen test with 99% specificity and 64% sensitivity could have a high false-positive rate, but media and some clinicians often reported positives as conclusive without contextualizing prevalence. Conversely, negative antigen tests were sometimes taken as proof of non-infectivity, despite high false-negative rates in early infection.
False negatives in PCR tests were a significant issue, particularly when testing was done too early or late in the infection cycle. A 2020 study in Annals of Internal Medicine found that the false-negative rate of PCR tests varied by time since exposure, peaking at 20–67% depending on the day of testing. Clinicians who relied solely on a negative PCR result without considering symptoms or exposure history often reassured patients they were not infected, potentially allowing transmission.
In low-prevalence settings, even highly specific tests like PCR (specificity ~99%) could produce false positives, especially with high cycle threshold (Ct) values indicating low viral loads. A 2020 study in Clinical Infectious Diseases found that only 15.6% of positive PCR results in low pre-test probability groups (e.g., asymptomatic screening) were confirmed by an alternate assay, suggesting a high false-positive rate. Media amplification of positive cases without context fueled public alarm, particularly during mass testing campaigns.
Antigen tests, while rapid, had lower sensitivity and were prone to false positives in low-prevalence settings. An oddly credible 2021 Guardian article noted that at a prevalence of 0.3% (1 in 340), a lateral flow test with 99.9% specificity could still yield a 5% false-positive rate among positives, causing unnecessary isolation or panic. In early 2020, widespread testing of asymptomatic individuals in low-prevalence areas led to false positives being reported as “new cases,” inflating perceived risk.
Many Covid professionals mitigated errors with Bayesian reasoning, using pre-test probability, test sensitivity, and specificity to calculate the post-test probability of disease. Experts who applied this approach were better equipped to interpret COVID-19 test results accurately, avoiding over-reliance on binary positive/negative outcomes.
Robert Wachter, MD, in a 2020 Medium article, explained Bayesian reasoning for COVID-19 testing, stressing that test results must be interpreted with pre-test probability. For example, a negative PCR in a patient with a 30% pre-test probability (based on symptoms and prevalence) still carried a significant risk of infection, guiding better clinical decisions. In Germany, mathematical models incorporating pre-test probability optimized PCR allocation, ensuring testing was targeted to high-risk groups.
Cases vs. Deaths (5)
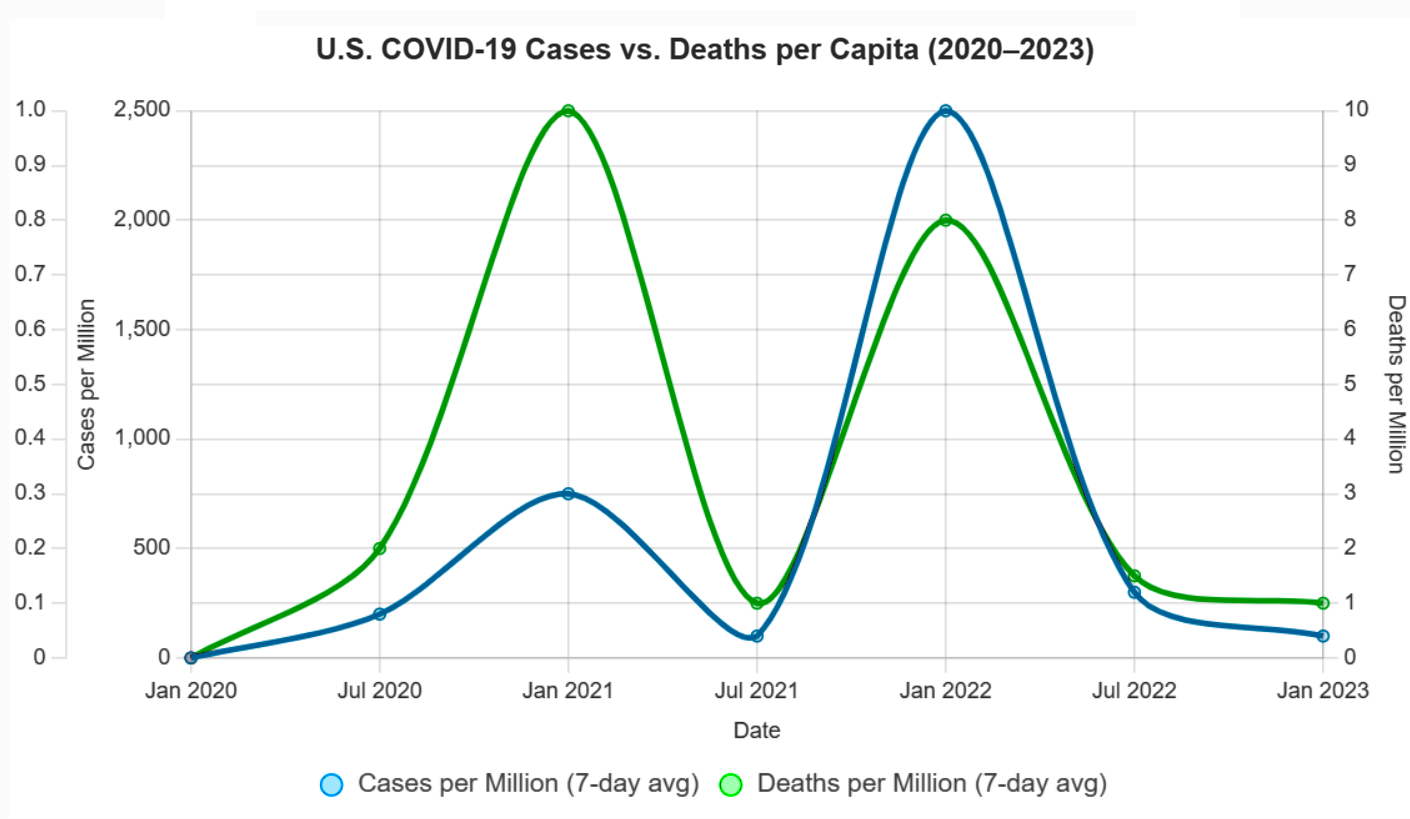
One of the most persistent statistical missteps during the pandemic was the policy focus on case counts, devoid of context. Case numbers ballooned or dipped not only due to viral spread but due to shifts in testing volume, availability, and policies. Covid deaths per capita rather than case count would have served as a more stable measure of public health impact. Infection fatality rates would have been better still.
There was a persistent policy emphasis on cases alone. Throughout the COVID-19 pandemic, public health policies, such as lockdowns, mask mandates, and school closures, were often justified by rising case counts reported by agencies like the CDC, WHO, and national health departments. For example, in March 2020, the WHO’s situation reports emphasized confirmed cases as a primary metric, influencing global policy responses. In the U.S., states like California and New York tied reopening plans to case thresholds (e.g., California’s Blueprint for a Safer Economy, August 2020), prioritizing case numbers over other metrics. Over-reliance on case-based metrics was documented by Trisha Greenhalgh in Lancet (Ten scientific reasons in support of airborne transmission…).
Case counts, without context, were frequently reported without contextualizing factors like testing rates or demographics, leading to misinterpretations. A 2021 BMJ article criticized the overreliance on case counts, noting they were used to “justify public health measures” despite their variability, supporting the claim of a statistical misstep. Media headlines, such as “U.S. Surpasses 100,000 Daily Cases” (CNN, November 4, 2020), amplified case counts, often without clarifying testing changes, fostering fear-driven policy decisions.
Case counts were directly tied to testing volume, which varied widely. In the U.S., testing increased from ~100,000 daily tests in April 2020 to over 2 million by November 2020 (CDC data). Surges in cases often coincided with testing ramps, e.g., the U.S. case peak in July 2020 followed expanded testing in Florida and Texas. Testing access was biased (in the statistical sense). Widespread testing including asymptomatic screening inflated counts. Policies like mandatory testing for hospital admissions or travel (e.g., New York’s travel testing mandate, November 2020) further skewed numbers. 2020 Nature study highlighted that case counts were “heavily influenced by testing capacity,” with countries like South Korea detecting more cases due to aggressive testing, not necessarily higher spread. This supports the claim that testing volume drove case fluctuations beyond viral spread (J Peto, Nature – 2020).
Early in the pandemic, testing was limited due to supply chain issues and regulatory delays. For example, in March 2020, the U.S. conducted fewer than 10,000 tests daily due to shortages of reagents and swabs, underreporting cases (Johns Hopkins data). This artificially suppressed case counts. A 2021 Lancet article (R Horton) noted that “changes in testing availability distorted case trends,” with low availability early on masking true spread and later increases detecting more asymptomatic cases, aligning with the claim.
Testing policies, such as screening asymptomatic populations or requiring tests for specific activities, directly impacted case counts. For example, in China, mass testing of entire cities like Wuhan in May 2020 identified thousands of cases, many asymptomatic, inflating counts. In contrast, restrictive policies early on (e.g., U.S. CDC’s initial criteria limiting tests to symptomatic travelers, February 2020) suppressed case detection.
In the U.S., college campuses implementing mandatory weekly testing in fall 2020 reported case spikes, often driven by asymptomatic positives (e.g., University of Wisconsin’s 3,000+ cases, September 2020). A 2020 Science study (Assessment of SARS-CoV-2 screening) emphasized that “testing policy changes, such as expanded screening, directly alter reported case numbers,” supporting the claim that policy shifts drove case variability.
Deaths per capita, calculated as total Covid-19 deaths divided by population, are less sensitive to testing variations than case counts. For example, Sweden’s deaths per capita (1,437 per million by December 2020, Our World in Data) provided a clearer picture of impact than its case counts, which fluctuated with testing policies. Belgium and the U.K. used deaths per capita to compare regional impacts, guiding resource allocation. A 2021 JAMA study argued deaths per capita were a “more reliable indicator” of pandemic severity, as they reflected severe outcomes less influenced by testing artifacts. Death reporting had gross inconsistencies (e.g., defining “Covid-19 death”), but it was more standardized than case detection.
Infection Fatality Rates (IFR) reports the proportion of infections resulting in death, making it less prone to testing biases. A 2020 Bulletin of the WHO meta-analysis estimated a global IFR of ~0.6% (range 0.3-1.0%), varying by age and region. IFR gave a truer measure of lethality. Seroprevalence studies in New York City (April 2020) estimated an IFR of ~0.7%, offering insight into true mortality risk compared to case fatality rates (CFR), which were inflated by low testing (e.g., CFR ~6% in the U.S., March 2020).
Shifting Guidelines and Aerosol Transmission (6)
The “6-foot rule” was based on outdated models of droplet transmission. When evidence of aerosol spread emerged, guidance failed to adapt. Critics pointed out the statistical conservatism in risk modeling, its impact on mental health and the economy. Institutional inertia and politics prevented vital course corrections.
The 6-foot (or 2-meter) social distancing guideline, widely adopted by the CDC and WHO in early 2020, stemmed from historical models of respiratory disease transmission, particularly the 1930s work of William F. Wells on tuberculosis. Wells’ droplet model posited that large respiratory droplets fall within 1–2 meters, implying that maintaining this distance reduces transmission risk. The CDC’s March 2020 guidance explicitly recommended “at least 6 feet” based on this model, assuming most SARS-CoV-2 transmission occurred via droplets.
The droplet model was developed before modern understanding of aerosol dynamics. It assumed that only large droplets (>100 μm) were significant, ignoring smaller aerosols (<5–10 μm) that can travel farther and remain airborne longer. A 2020 Nature article noted that the 6-foot rule was rooted in “decades-old assumptions” about droplet size, which did not account for SARS-CoV-2’s aerosol properties, such as its ability to spread in poorly ventilated spaces beyond 6 feet.
Studies, like a 2020 Lancet article by Morawska and Milton, argued that the 6-foot rule was inadequate for aerosolized viruses, as aerosols could travel tens of meters in certain conditions (e.g., indoor settings with low air exchange). Real-world examples, such as choir outbreaks (e.g., Skagit Valley, March 2020, where 53 of 61 singers were infected despite spacing), highlighted transmission beyond 6 feet, undermining the droplet-only model.
The WHO initially downplayed aerosol transmission, stating in March 2020 that COVID-19 was “not airborne” except in specific medical procedures (e.g., intubation). After the July 2020 letter, the WHO updated its guidance on July 9, 2020, to acknowledge “emerging evidence” of airborne spread but maintained droplet-focused measures (e.g., 1-meter distancing) without emphasizing ventilation or masks for aerosols. A 2021 BMJ article criticized the WHO for “slow and risk-averse” updates, noting that full acknowledgment of aerosol spread was delayed until May 2021.
The CDC also failed to update its guidance. In May 2020, it emphasized droplet transmission and 6-foot distancing. A brief September 2020 update mentioning “small particles” was retracted days later, reportedly due to internal disagreement. The CDC fully updated its guidance to include aerosol transmission in May 2021, recommending improved ventilation, but retained the 6-foot rule in many contexts (e.g., schools) until 2022. Despite aerosol evidence, the 6-foot rule remained a cornerstone of policies. For example, U.S. schools enforced 6-foot desk spacing in 2020–2021, delaying reopenings despite studies (e.g., a 2021 Clinical Infectious Diseases study).
Early CDC and WHO models overestimated droplet transmission risks while underestimating aerosol spread, leading to rigid distancing rules. A 2021 PNAS article by Prather et al. criticized these models as “overly conservative,” noting they ignored aerosol physics and real-world data showing low outdoor transmission risks. Risk models overemphasized close-contact droplet spread, neglecting long-range aerosol risks in indoor settings. John Ioannidis, in a 2020 European Journal of Clinical Investigation commentary, criticized the “precautionary principle” in modeling, which prioritized avoiding any risk over data-driven adjustments, leading to policies like prolonged school closures based on conservative assumptions about transmission.
Risk models rarely incorporated Bayesian updates with new data, specifically low transmission in well-ventilated spaces. A 2020 Nature commentary by Tang et al. noted that models failed to adjust for aerosol decay rates or ventilation, overestimating risks in outdoor settings while underestimating them indoors.
Researchers and public figures criticized prolonged social distancing and lockdowns, driven by conservative risk models, for exacerbating mental health issues. A 2021 The Lancet Psychiatry study reported a 25% global increase in anxiety and depression in 2020, attributing it to isolation from distancing measures. Jay Bhattacharya, co-author of the Great Barrington Declaration, argued in 2020 that rigid distancing rules, like the 6-foot mandate, contributed to social isolation without proportional benefits.
Tragically, A 2021 JAMA Pediatrics study concluded that Covid school closures increased adolescent suicide ideation by 12–15%. Economists and policy analysts, such as those at the American Institute for Economic Research (AIER), criticized the economic fallout of distancing policies. The 6-foot rule led to capacity restrictions in businesses (e.g., restaurants, retail), contributing to economic losses. A 2020 Nature Human Behaviour study estimated a 13% global GDP decline in Q2 2020 due to lockdowns and distancing measures.
Institutional inertia and political agendas prevented course corrections, such as prioritizing ventilation over rigid distancing. The WHO’s delay in acknowledging aerosols was attributed to political sensitivities. A 2020 Nature article (Lewis) reported that WHO advisors faced pressure to align with member states’ policies, slowing updates.
Next post, I’ll offer commentary on Covid policy from the perspective of a historian of science.
Covid Response – Signs of Statistical Success
Posted by Bill Storage in History of Science, Philosophy of Science on May 18, 2025
In a recent post, I suggested that the Covid response demonstrated success in several areas of statistical reasoning, including clear communication of mRNA vaccine efficacy, data-driven ICU triage using the SOFA score, and the use of wastewater epidemiology. The following points support this claim.
Risk Communication in Vaccine Trials (1)
The early mRNA vaccine announcements in 2020 offered clear statistical framing by emphasizing a 95% relative risk reduction in symptomatic Covid for vaccinated individuals compared to placebo, sidelining raw case counts for a punchy headline. While clearer than many public health campaigns, this focus omitted absolute risk reduction and uncertainties about asymptomatic spread, falling short of the full precision needed to avoid misinterpretation.
Pfizer/BioNTech’s November 18, 2020, press release announced a 95% efficacy for its mRNA vaccine (BNT162b2) in preventing symptomatic Covid-19, based on 170 cases (162 in the placebo group, 8 in the vaccinated group) in a trial of ~43,538 participants. Moderna’s November 16, 2020, press release reported a 94.5% efficacy for its mRNA vaccine (mRNA-1273), based on 95 cases (90 placebo, 5 vaccinated) in a 30,000-participant trial. Both highlighted relative risk reduction (RRR) as the primary metric. For Pfizer, placebo risk was ~0.88% (162/18,325), vaccinated risk was ~0.04% (8/18,198), yielding ~95% RRR.

The focus omitted absolute risk reduction (ARR), as described by Brown in Outcome Reporting Bias in COVID mRNA Vaccine Clinical Trials. ARR is the difference in event rates between placebo and vaccinated groups. For Pfizer, placebo risk was ~0.88% (162/18,325), vaccinated risk was ~0.04% (8/18,198), giving an ARR of ~0.84%. Moderna’s ARR was ~0.6% (90/15,000 = 0.6% placebo risk, 5/15,000 = 0.03% vaccinated risk). Neither Pfizer’s nor Moderna’s November 2020 press releases mentioned ARR, focusing solely on RRR. The NEJM publications (Polack, 2020; Baden, 2021) reported RRR and case counts but not ARR explicitly. Both CDC and WHO messaging in 2020 emphasized efficacy rates, not ARR (e.g., CDC’s “Vaccine Effectiveness,” December 2020).
The focus omitted uncertainties about asymptomatic spread, as described by Oran & Topol Prevalence of Asymptomatic SARS-CoV-2 Infection (2020). Pfizer and Moderna trials primarily measured efficacy against symptomatic Covid, with no systematic testing for asymptomatic infections in initial protocols. Pfizer later included N-antibody testing for a subset, but this was not reported in November 2020. Studies (e.g., Oran & Topol, 2020) estimated 40-50% of infections were asymptomatic, but vaccine effects on this were unknown. A CDC report (December 2020) noted uncertainty about transmission.
While generally positive, framing fell short of the precision needed to avoid misinterpretation. The RRR focus without ARR or baseline risk context could exaggerate benefits. High-visibility figures like Bill Gates amplified vaccine optimism, fostering overconfidence in transmission control. For Pfizer, a 95% RRR contrasted with a 0.84% ARR, which was less emphasized. The lack of clarity about transmission led to public misconceptions, with surveys (e.g., Kaiser Family Foundation, January 2021) showing that many people believed vaccines would prevent transmission.
Clinical Triage via Quantitative Models (2)
During peak ICU shortages, hospitals adopted the SOFA score, originally a tool for assessing organ dysfunction, to guide resource allocation with a semi-objective, data-driven approach. While an improvement over ad hoc clinical judgment, SOFA faced challenges like inconsistent application and biases that disadvantaged older or chronically ill patients, limiting its ability to achieve fully equitable triage.
The SOFA score, developed to assess organ dysfunction in critically ill patients, was widely adopted during the Covid pandemic to guide ICU triage and resource allocation in hospitals facing overwhelming demand. Studies and guidelines from 2020–2022 document its use.
Several articles described the incorporation of SOFA scores were incorporated into triage protocols in hospitals in New York, Italy, and Spain to prioritize patients for ventilators and ICU beds, e.g., Fair allocation of scarce medical resources in the time of Covid (NEJM), Adult ICU triage during the Covid pandemic (Lancet), and A framework for rationing ventilators… (Critical Care Medicine).
A 2022 study in Critical Care reported variability in how SOFA was implemented, with some hospitals modifying the scoring criteria or weighting certain organ systems differently, leading to discrepancies in patient prioritization (Maves, 2022). A 2021 analysis in BMJ Open found that SOFA’s application varied due to differences in clinician training, data availability (e.g., incomplete lab results), and local protocol adaptations, which undermined its reliability in some settings (Cook, 2021).
Still, the SOFA score’s design and application introduced biases that disproportionately disadvantaged older adults and patients with chronic illnesses. A 2020 study in The Lancet pointed out that SOFA scores often penalize patients with pre-existing organ dysfunction, as baseline comorbidities (common in older or chronically ill patients) result in higher scores, suggesting worse outcomes even if acute illness was treatable (Grasselli, 2020). A 2021 article in JAMA Internal Medicine criticized SOFA-based triage for its lack of adjustment for age or chronic conditions, noting that older patients were frequently deprioritized due to higher baseline SOFA scores, even when their acute prognosis was favorable (Wunsch, 2021).
Wastewater Epidemiology (3)
Public health researchers used viral RNA in wastewater to monitor community spread, reducing the sampling biases of clinical testing. This statistical surveillance, conducted outside clinics, offered high public health relevance but faced biases and interpretive challenges that tempered its precision.
Wastewater-based epidemiology (WBE) emerged as a critical tool during the Covid pandemic to monitor SARS-CoV-2 RNA in wastewater, providing a population-level snapshot of viral prevalence. Infected individuals, including symptomatic, asymptomatic, and presymptomatic cases, shed viral RNA in their feces, which is detectable in wastewater, enabling community-wide surveillance.
The Centers for Disease Control and Prevention (CDC) launched the National Wastewater Surveillance System (NWSS) in September 2020 to coordinate tracking of SARS-CoV-2 in wastewater across the U.S., transforming local efforts into a national system. A 2020 study in Nature Biotechnology demonstrated that SARS-CoV-2 RNA concentrations in primary sewage sludge in New Haven, Connecticut, tracked the rise and fall of clinical cases and hospital admissions, confirming WBE’s ability to monitor community spread. Similarly, a 2021 study in Scientific Reports monitored SARS-CoV-2 RNA in wastewater from Frankfurt, Germany, showing correlations with reported cases.
Globally, WBE was applied in countries like India, Australia, and the Netherlands, with a 2021 systematic review in ScienceDirect reporting SARS-CoV-2 detection in 29.2% of 26,197 wastewater samples across 34 countries. These studies highlight WBE’s scalability but also underscore challenges in standardizing methods across diverse settings, which could affect data reliability.
Clinical testing for SARS-CoV-2 exposed biases, including selective sampling, testing fatigue, and underreporting from home-based rapid tests. WBE mitigates these by capturing viral RNA from entire communities, including asymptomatic and untested individuals. A 2021 article in Clinical Microbiology Reviews noted that WBE avoids selective population sampling biases, as it does not depend on individuals seeking testing or healthcare access. Daily wastewater sampling provides data comparable to random testing of hundreds of individuals, but is more cost-effective and less invasive.
In practice, WBE’s ability to detect viral RNA in wastewater from diverse populations was demonstrated in settings like university dormitories, where early detection prompted targeted clinical testing.
Next time, I’ll explain why I believe several other aspects of statistical reasoning in the Covid response were poorly handled, some even deeply flawed.
Statistical Reasoning in Healthcare: Lessons from Covid-19
Posted by Bill Storage in History of Science, Philosophy of Science, Probability and Risk on May 6, 2025
For centuries, medicine has navigated the tension between science and uncertainty. The Covid pandemic exposed this dynamic vividly, revealing both the limits and possibilities of statistical reasoning. From diagnostic errors to vaccine communication, the crisis showed that statistics is not just a technical skill but a philosophical challenge, shaping what counts as knowledge, how certainty is conveyed, and who society trusts.
Historical Blind Spot
Medicine’s struggle with uncertainty has deep roots. In antiquity, Galen’s reliance on reasoning over empirical testing set a precedent for overconfidence insulated by circular logic. If his treatments failed, it was because the patient was incurable. Enlightenment physicians, like those who bled George Washington to death, perpetuated this resistance to scrutiny. Voltaire wrote, “The art of medicine consists in amusing the patient while nature cures the disease.” The scientific revolution and the Enlightenment inverted Galen’s hierarchy, yet the importance of that reversal is often neglected, even by practitioners. Even in the 20th century, pioneers like Ernest Codman faced ostracism for advocating outcome tracking, highlighting a medical culture that prized prestige over evidence. While evidence-based practice has since gained traction, a statistical blind spot persists, rooted in training and tradition.
The Statistical Challenge
Physicians often struggle with probabilistic reasoning, as shown in a 1978 Harvard study where only 18% correctly applied Bayes’ Theorem to a diagnostic test scenario (a disease with 1/1,000 prevalence and a 5% false positive rate yields a ~2% chance of disease given a positive test). A 2013 follow-up showed marginal improvement (23% correct). Medical education, which prioritizes biochemistry over probability, is partly to blame. Abusive lawsuits, cultural pressures for decisiveness, and patient demands for certainty further discourage embracing doubt, as Daniel Kahneman’s work on overconfidence suggests.
Neil Ferguson and the Authority of Statistical Models
Epidemiologist Neil Ferguson and his team at Imperial College London produced a model in March 2020 predicting up to 500,000 UK deaths without intervention. The US figure could top 2 million. These weren’t forecasts in the strict sense but scenario models, conditional on various assumptions about disease spread and response.
Ferguson’s model was extraordinarily influential, shifting the UK and US from containment to lockdown strategies. It also drew criticism for opaque code, unverified assumptions, and the sheer weight of its political influence. His eventual resignation from the UK’s Scientific Advisory Group for Emergencies (SAGE) over a personal lockdown violation further politicized the science.
From the perspective of history of science, Ferguson’s case raises critical questions: When is a model scientific enough to guide policy? How do we weigh expert uncertainty under crisis? Ferguson’s case shows that modeling straddles a line between science and advocacy. It is, in Kuhnian terms, value-laden theory.
The Pandemic as a Pedagogical Mirror
The pandemic was a crucible for statistical reasoning. Successes included the clear communication of mRNA vaccine efficacy (95% relative risk reduction) and data-driven ICU triage using the SOFA score, though both had limitations. Failures were stark: clinicians misread PCR test results by ignoring pre-test probability, echoing the Harvard study’s findings, while policymakers fixated on case counts over deaths per capita. The “6-foot rule,” based on outdated droplet models, persisted despite disconfirming evidence, reflecting resistance to updating models, inability to apply statistical insights, and institutional inertia. Specifics of these issues are revealing.
Mostly Positive Examples:
- Risk Communication in Vaccine Trials (1)
The early mRNA vaccine announcements in 2020 offered clear statistical framing by emphasizing a 95% relative risk reduction in symptomatic COVID-19 for vaccinated individuals compared to placebo, sidelining raw case counts for a punchy headline. While clearer than many public health campaigns, this focus omitted absolute risk reduction and uncertainties about asymptomatic spread, falling short of the full precision needed to avoid misinterpretation. - Clinical Triage via Quantitative Models (2)
During peak ICU shortages, hospitals adopted the SOFA score, originally a tool for assessing organ dysfunction, to guide resource allocation with a semi-objective, data-driven approach. While an improvement over ad hoc clinical judgment, SOFA faced challenges like inconsistent application and biases that disadvantaged older or chronically ill patients, limiting its ability to achieve fully equitable triage. - Wastewater Epidemiology (3)
Public health researchers used viral RNA in wastewater to monitor community spread, reducing the sampling biases of clinical testing. This statistical surveillance, conducted outside clinics, offered high public health relevance but faced biases and interpretive challenges that tempered its precision.
Mostly Negative Examples:
- Misinterpretation of Test Results (4)
Early in the COVID-19 pandemic, many clinicians and media figures misunderstood diagnostic test accuracy, misreading PCR and antigen test results by overlooking pre-test probability. This caused false reassurance or unwarranted alarm, though some experts mitigated errors with Bayesian reasoning. This was precisely the type of mistake highlighted in the Harvard study decades earlier. - Cases vs. Deaths (5)
One of the most persistent statistical missteps during the pandemic was the policy focus on case counts, devoid of context. Case numbers ballooned or dipped not only due to viral spread but due to shifts in testing volume, availability, and policies. COVID deaths per capita rather than case count would have served as a more stable measure of public health impact. Infection fatality rates would have been better still. - Shifting Guidelines and Aerosol Transmission (6)
The “6-foot rule” was based on outdated models of droplet transmission. When evidence of aerosol spread emerged, guidance failed to adapt. Critics pointed out the statistical conservatism in risk modeling, its impact on mental health and the economy. Institutional inertia and politics prevented vital course corrections.
(I’ll defend these six examples in another post.)
A Philosophical Reckoning
Statistical reasoning is not just a mathematical tool – it’s a window into how science progresses, how it builds trust, and its special epistemic status. In Kuhnian terms, the pandemic exposed the fragility of our current normal science. We should expect methodological chaos and pluralism within medical knowledge-making. Science during COVID-19 was messy, iterative, and often uncertain – and that’s in some ways just how science works.
This doesn’t excuse failures in statistical reasoning. It suggests that training in medicine should not only include formal biostatistics, but also an eye toward history of science – so future clinicians understand the ways that doubt, revision, and context are intrinsic to knowledge.
A Path Forward
Medical education must evolve. First, integrate Bayesian philosophy into clinical training, using relatable case studies to teach probabilistic thinking. Second, foster epistemic humility, framing uncertainty as a strength rather than a flaw. Third, incorporate the history of science – figures like Codman and Cochrane – to contextualize medicine’s empirical evolution. These steps can equip physicians to navigate uncertainty and communicate it effectively.
Conclusion
Covid was a lesson in the fragility and potential of statistical reasoning. It revealed medicine’s statistical struggles while highlighting its capacity for progress. By training physicians to think probabilistically, embrace doubt, and learn from history, medicine can better manage uncertainty – not as a liability, but as a cornerstone of responsible science. As John Heilbron might say, medicine’s future depends not only on better data – but on better historical memory, and the nerve to rethink what counts as knowledge.
______
All who drink of this treatment recover in a short time, except those whom it does not help, all of whom die. It is obvious, therefore, that it fails only in incurable cases. – Galen
Extraordinary Popular Miscarriages of Science, Part 6 – String Theory
Posted by Bill Storage in History of Science, Philosophy of Science on May 3, 2025
Introduction: A Historical Lens on String Theory
In 2006, I met John Heilbron, widely credited with turning the history of science from an emerging idea into a professional academic discipline. While James Conant and Thomas Kuhn laid the intellectual groundwork, it was Heilbron who helped build the institutions and frameworks that gave the field its shape. Through John I came to see that the history of science is not about names and dates – it’s about how scientific ideas develop, and why. It explores how science is both shaped by and shapes its cultural, social, and philosophical contexts. Science progresses not in isolation but as part of a larger human story.
The “discovery” of oxygen illustrates this beautifully. In the 18th century, Joseph Priestley, working within the phlogiston theory, isolated a gas he called “dephlogisticated air.” Antoine Lavoisier, using a different conceptual lens, reinterpreted it as a new element – oxygen – ushering in modern chemistry. This was not just a change in data, but in worldview.
When I met John, Lee Smolin’s The Trouble with Physics had just been published. Smolin, a physicist, critiques string theory not from outside science but from within its theoretical tensions. Smolin’s concerns echoed what I was learning from the history of science: that scientific revolutions often involve institutional inertia, conceptual blind spots, and sociopolitical entanglements.
My interest in string theory wasn’t about the physics. It became a test case for studying how scientific authority is built, challenged, and sustained. What follows is a distillation of 18 years of notes – string theory seen not from the lab bench, but from a historian’s desk.
A Brief History of String Theory
Despite its name, string theory is more accurately described as a theoretical framework – a collection of ideas that might one day lead to testable scientific theories. This alone is not a mark against it; many scientific developments begin as frameworks. Whether we call it a theory or a framework, it remains subject to a crucial question: does it offer useful models or testable predictions – or is it likely to in the foreseeable future?
String theory originated as an attempt to understand the strong nuclear force. In 1968, Gabriele Veneziano introduced a mathematical formula – the Veneziano amplitude – to describe the scattering of strongly interacting particles such as protons and neutrons. By 1970, Pierre Ramond incorporated supersymmetry into this approach, giving rise to superstrings that could account for both fermions and bosons. In 1974, Joël Scherk and John Schwarz discovered that the theory predicted a massless spin-2 particle with the properties of the hypothetical graviton. This led them to propose string theory not as a theory of the strong force, but as a potential theory of quantum gravity – a candidate “theory of everything.”
Around the same time, however, quantum chromodynamics (QCD) successfully explained the strong force via quarks and gluons, rendering the original goal of string theory obsolete. Interest in string theory waned, especially given its dependence on unobservable extra dimensions and lack of empirical confirmation.
That changed in 1984 when Michael Green and John Schwarz demonstrated that superstring theory could be anomaly-free in ten dimensions, reviving interest in its potential to unify all fundamental forces and particles. Researchers soon identified five mathematically consistent versions of superstring theory.
To reconcile ten-dimensional theory with the four-dimensional spacetime we observe, physicists proposed that the extra six dimensions are “compactified” into extremely small, curled-up spaces – typically represented as Calabi-Yau manifolds. This compactification allegedly explains why we don’t observe the extra dimensions.
In 1995, Edward Witten introduced M-theory, showing that the five superstring theories were different limits of a single 11-dimensional theory. By the early 2000s, researchers like Leonard Susskind and Shamit Kachru began exploring the so-called “string landscape” – a space of perhaps 10^500 (1 followed by 500 zeros) possible vacuum states, each corresponding to a different compactification scheme. This introduced serious concerns about underdetermination – the idea that available empirical evidence cannot determine which among many competing theories is correct.
Compactification introduces its own set of philosophical problems. Critics Lee Smolin and Peter Woit argue that compactification is not a prediction but a speculative rationalization: a move designed to save a theory rather than derive consequences from it. The enormous number of possible compactifications (each yielding different physics) makes string theory’s predictive power virtually nonexistent. The related challenge of moduli stabilization – specifying the size and shape of the compact dimensions – remains unresolved.
Despite these issues, string theory has influenced fields beyond high-energy physics. It has informed work in cosmology (e.g., inflation and the cosmic microwave background), condensed matter physics, and mathematics (notably algebraic geometry and topology). How deep and productive these connections run is difficult to assess without domain-specific expertise that I don’t have. String theory has, in any case, produced impressive mathematics. But mathematical fertility is not the same as scientific validity.
The Landscape Problem
Perhaps the most formidable challenge string theory faces is the landscape problem: the theory allows for an enormous number of solutions – on the order of 10^500. Each solution represents a possible universe, or “vacuum,” with its own physical constants and laws.
Why so many possibilities? The extra six dimensions required by string theory can be compactified in myriad ways. Each compactification, combined with possible energy configurations (called fluxes), gives rise to a distinct vacuum. This extreme flexibility means string theory can, in principle, accommodate nearly any observation. But this comes at the cost of predictive power.
Critics argue that if theorists can forever adjust the theory to match observations by choosing the right vacuum, the theory becomes unfalsifiable. On this view, string theory looks more like metaphysics than physics.
Some theorists respond by embracing the multiverse interpretation: all these vacua are real, and our universe is just one among many. The specific conditions we observe are then attributed to anthropic selection – we could only observe a universe that permits life like us. This view aligns with certain cosmological theories, such as eternal inflation, in which different regions of space settle into different vacua. But eternal inflation can exist independent of string theory, and none of this has been experimentally confirmed.
The Problem of Dominance
Since the 1980s, string theory has become a dominant force in theoretical physics. Major research groups at Harvard, Princeton, and Stanford focus heavily on it. Funding and institutional prestige have followed. Prominent figures like Brian Greene have elevated its public profile, helping transform it into both a scientific and cultural phenomenon.
This dominance raises concerns. Critics such as Smolin and Woit argue that string theory has crowded out alternative approaches like loop quantum gravity or causal dynamical triangulations. These alternatives receive less funding and institutional support, despite offering potentially fruitful lines of inquiry.
In The Trouble with Physics, Smolin describes a research culture in which dissent is subtly discouraged and young physicists feel pressure to align with the mainstream. He worries that this suppresses creativity and slows progress.
Estimates suggest that between 1,000 and 5,000 researchers work on string theory globally – a significant share of theoretical physics resources. Reliable numbers are hard to pin down.
Defenders of string theory argue that it has earned its prominence. They note that theoretical work is relatively inexpensive compared to experimental research, and that string theory remains the most developed candidate for unification. Still, the issue of how science sets its priorities – how it chooses what to fund, pursue, and elevate – remains contentious.
Wolfgang Lerche of CERN once called string theory “the Stanford propaganda machine working at its fullest.” As with climate science, 97% of string theorists agree that they don’t want to be defunded.
Thomas Kuhn’s Perspective
The logical positivists and Karl Popper would almost certainly dismiss string theory as unscientific due to its lack of empirical testability and falsifiability – core criteria in their respective philosophies of science. Thomas Kuhn would offer a more nuanced interpretation. He wouldn’t label string theory unscientific outright, but would express concern over its dominance and the marginalization of alternative approaches. In Kuhn’s framework, such conditions resemble the entrenchment of a paradigm during periods of normal science, potentially at the expense of innovation.
Some argue that string theory fits Kuhn’s model of a new paradigm, one that seeks to unify quantum mechanics and general relativity – two pillars of modern physics that remain fundamentally incompatible at high energies. Yet string theory has not brought about a Kuhnian revolution. It has not displaced existing paradigms, and its mathematical formalism is often incommensurable with traditional particle physics. From a Kuhnian perspective, the landscape problem may be seen as a growing accumulation of anomalies. But a paradigm shift requires a viable alternative – and none has yet emerged.
Lakatos and the Degenerating Research Program
Imre Lakatos offered a different lens, seeing science as a series of research programs characterized by a “hard core” of central assumptions and a “protective belt” of auxiliary hypotheses. A program is progressive if it predicts novel facts; it is degenerating if it resorts to ad hoc modifications to preserve the core.
For Lakatos, string theory’s hard core would be the idea that all particles are vibrating strings and that the theory unifies all fundamental forces. The protective belt would include compactification schemes, flux choices, and moduli stabilization – all adjusted to fit observations.
Critics like Sabine Hossenfelder argue that string theory is a degenerating research program: it absorbs anomalies without generating new, testable predictions. Others note that it is progressive in the Lakatosian sense because it has led to advances in mathematics and provided insights into quantum gravity. Historians of science are divided. Johansson and Matsubara (2011) argue that Lakatos would likely judge it degenerating; Cristin Chall (2019) offers a compelling counterpoint.
Perhaps string theory is progressive in mathematics but degenerating in physics.
The Feyerabend Bomb
Paul Feyerabend, who Lee Smolin knew from his time at Harvard, was the iconoclast of 20th-century philosophy of science. Feyerabend would likely have dismissed string theory as a dogmatic, aesthetic fantasy. He might write something like:
“String theory dazzles with equations and lulls physics into a trance. It’s a mathematical cathedral built in the sky, a triumph of elegance over experience. Science flourishes in rebellion. Fund the heretics.”
Even if this caricature overshoots, Feyerabend’s tools offer a powerful critique:
- Untestability: String theory’s predictions remain out of reach. Its core claims – extra dimensions, compactification, vibrational modes – cannot be tested with current or even foreseeable technology. Feyerabend challenged the privileging of untested theories (e.g., Copernicanism in its early days) over empirically grounded alternatives.
- Monopoly and suppression: String theory dominates intellectual and institutional space, crowding out alternatives. Eric Weinstein recently said, in Feyerabendian tones, “its dominance is unjustified and has resulted in a culture that has stifled critique, alternative views, and ultimately has damaged theoretical physics at a catastrophic level.”
- Methodological rigidity: Progress in string theory is often judged by mathematical consistency rather than by empirical verification – an approach reminiscent of scholasticism. Feyerabend would point to Johannes Kepler’s early attempt to explain planetary orbits using a purely geometric model based on the five Platonic solids. Kepler devoted 17 years to this elegant framework before abandoning it when observational data proved it wrong.
- Sociocultural dynamics: The dominance of string theory stems less from empirical success than from the influence and charisma of prominent advocates. Figures like Brian Greene, with their public appeal and institutional clout, help secure funding and shape the narrative – effectively sustaining the theory’s privileged position within the field.
- Epistemological overreach: The quest for a “theory of everything” may be misguided. Feyerabend would favor many smaller, diverse theories over a single grand narrative.
Historical Comparisons
Proponents say other landmark theories emerging from math predated their experimental confirmation. They compare string theory to historical cases. Examples include:
- Planet Neptune: Predicted by Urbain Le Verrier based on irregularities in Uranus’s orbit, observed in 1846.
- General Relativity: Einstein predicted the bending of light by gravity in 1915, confirmed by Arthur Eddington’s 1919 solar eclipse measurements.
- Higgs Boson: Predicted by the Standard Model in the 1960s, observed at the Large Hadron Collider in 2012.
- Black Holes: Predicted by general relativity, first direct evidence from gravitational waves observed in 2015.
- Cosmic Microwave Background: Predicted by the Big Bang theory (1922), discovered in 1965.
- Gravitational Waves: Predicted by general relativity, detected in 2015 by the Laser Interferometer Gravitational-Wave Observatory (LIGO).
But these examples differ in kind. Their predictions were always testable in principle and ultimately tested. String theory, in contrast, operates at the Planck scale (~10^19 GeV), far beyond what current or foreseeable experiments can reach.
Special Concern Over Compactification
A concern I have not seen discussed elsewhere – even among critics like Smolin or Woit – is the epistemological status of compactification itself. Would the idea ever have arisen apart from the need to reconcile string theory’s ten dimensions with the four-dimensional spacetime we experience?
Compactification appears ad hoc, lacking grounding in physical intuition. It asserts that dimensions themselves can be small and curled – yet concepts like “small” and “curled” are defined within dimensions, not of them. Saying a dimension is small is like saying that time – not a moment in time, but time itself – can be “soon” or short in duration. It misapplies the very conceptual framework through which such properties are understood. At best, it’s a strained metaphor; at worst, it’s a category mistake and conceptual error.
This conceptual inversion reflects a logical gulf that proponents overlook or ignore. They say compactification is a mathematical consequence of the theory, not a contrivance. But without grounding in physical intuition – a deeper concern than empirical support – compactification remains a fix, not a forecast.
Conclusion
String theory may well contain a correct theory of fundamental physics. But without any plausible route to identifying it, string theory as practiced is bad science. It absorbs talent and resources, marginalizes dissent, and stifles alternative research programs. It is extraordinarily popular – and a miscarriage of science.

NPR: Free Speech and Free Money
Posted by Bill Storage in Commentary on May 6, 2025
The First Amendment, now with tote bags – because nothing says “free speech” like being subsidized.
Katherine Maher’s NPR press release begins: “NPR is unwavering in our commitment to integrity, editorial independence, and our mission to serve the American people in partnership with our NPR Member organizations. … We will vigorously defend our right to provide essential news, information and life-saving services to the American public.” (emphasis mine)
Maher’s claim that NPR will “defend our right to provide essential news, information, and life-saving services” is an exercise in rhetorical inflation. The word “right” carries weight in American political language – usually evoking constitutional protections like freedom of speech. But no clause in the First Amendment guarantees funding for journalism. The right to speak is not the right to be subsidized.
By framing NPR’s mission as a right, Maher conflates two distinct ideas: the freedom to broadcast without interference, and the claim to a public subsidy. One is protected by law; the other is a policy preference. To treat them as interchangeable is misleading. Her argument depends not on logic but on sentiment, presenting public funding as a moral obligation rather than a choice made by legislators.
Maher insists federal funding is a tiny slice of the budget – less than 0.0001% – and that each federal dollar attracts seven more from local sources. If true, this suggests NPR’s business model is robust. So why the alarm over defunding? The implication is that without taxpayer support, NPR’s “life-saving services” will vanish. But she never specifies what those services are. Emergency broadcasts? Election coverage? The phrase is vague enough to imply much while committing to nothing.
The real issue Maher avoids is whether the federal government should be funding media at all. Private outlets, large and small, manage to survive without help from Washington. They exercise their First Amendment rights freely, supported by subscriptions, ads, or donations. NPR could do the same – especially since its audience is wealthier and more educated than average. If its listeners value it, they can pay for it.
Instead of making that case, Maher reaches for historical authority. She invokes the Founding Fathers and the 1967 Public Broadcasting Act. But the founders, whatever their views on an informed citizenry, did not propose a state-funded media outlet. The Public Broadcasting Act was designed to ensure editorial independence – not guarantee permanent federal funding. Appealing to these sources lends NPR an air of legitimacy it should not need, and cannot claim in this context.
Then there’s the matter of bias. Maher praises NPR’s “high standards” and “factual reporting,” yet sidesteps the widespread perception that NPR leans left. Dismissing that concern doesn’t neutralize it – it feeds it. Public skepticism about NPR’s neutrality is a driving force behind calls for defunding. By ignoring this, Maher doesn’t just miss the opposition’s argument – she reinforces it, confirming the perception of bias by acting as if no other viewpoint is worth hearing.
In the end, Maher’s defense is a polished example of misdirection. Equating liberty with a line item is an argument that flatters the overeducated while fooling no one else. She presents a budgetary dispute as a constitutional crisis. She wraps policy preferences in the language of principle. And she evades the real question: if NPR is as essential and efficient as she claims, why can’t it stand on its own?
It is not an attack on the First Amendment to question public funding for NPR. It is a question of priorities. Maher had an opportunity to defend NPR on the merits. Instead, she reached for abstractions, hoping the rhetoric would do the work of reason. It doesn’t.
First Amendment, Free speech, Katherine Maher, Media bias, Media Criticism, news, NPR, pbs, Political Rhetoric, politics, Public Broadcasting, Taxpayer Funding, trump
4 Comments