Seven Holes in the Head
Posted by Bill Storage in History of Science on July 21, 2026
Galileo, Order, and the Persistence of Reasoning through Aesthetics
Sunflowers follow the sun across the sky, and the moon controls the tides. Move a magnet over iron filings and the iron responds. You’ve already accepted action at a distance and celestial influence. Why dismiss planetary influence on human disposition outright?
In 1610 Galileo published Sidereus Nuncius, announcing discovery of four moons of Jupiter, which he called the Medicean Stars to flatter his patron. Scholars were divided. A contemporary astronomer, Francesco Sizzi, authored a small treatise in response, Dianoia Astronomica.
No summary of Sizzi’s reasoning does it justice. You need it in his words.
Just as in the microcosm there are seven ‘windows’ in the head (two nostrils, two eyes, two ears, and a mouth), so in the macrocosm God has placed two beneficent stars, two maleficent stars, two luminaries (sun and moon), and one indifferent. The seven days of the week follow from these. Finally, since ancient times the alchemists had made each of the seven metals correspond to one of the planets; gold to the sun, silver to the moon, copper to Venus, quicksilver to Mercury, iron to Mars, tin to Jupiter, lead to Saturn.
From these and many other similar phenomena of nature such as the seven metals, we gather that the number of planets is necessarily seven… Besides, the Jews and other ancient nations as well as modern Europeans, have adopted the division of the week into seven days, and have named them from the seven planets; now if we increase the number of planets, this whole system falls to the ground… Moreover, the satellites [of Jupiter] are invisible to the naked eye and therefore can have no influence on the earth, and therefore would be useless, and therefore do not exist.
There’s reasoning for you. Seven planets. Seven holes in the head. Case closed.
Today we know how the sunflower works. We know about phototropism, auxins, differential growth rates. We understand the mechanism. Francesco Sizzi didn’t.
His world system was built on regularities, from which he inferred relationships. He saw a universe whose underlying order could be read from recurring patterns.
For Sizzi, the universe was built upon sevens: seven planets, seven metals, seven days of the week, seven openings in the head. The cosmic order was complete. Galileo’s discovery was disruptive.
For a 16th century investigator of natural phenomena, the burden of proof was on the skeptic of long-held astrological knowledge. One reason astrology hung on so long was that no one came up with a satisfactory account of causation itself. In the 18th century, philosopher David Hume demolished the notion that we directly perceive causal necessity. We still debate what causation ultimately is. Like Sizzi, we observe regularities. We infer causes.
Sizzi was not defending ignorance. He was defending a conception of reality – and giving a nod to Pragmatism, a philosophy that wouldn’t emerge for another 300 years. The cosmos, as he understood it, was a web of correspondences. Harmony was the evidence. Symmetry meant something. The recurrence of patterns across different domains was evidence of a cosmic order. Rejecting those patterns in favor of four pinpoints of light visible only through a novel instrument did not seem rational.
We hold up Galileo as an example of speaking evidence to power. But most of us don’t reason as Galileo did.
We, like Sizzi, are drawn to elegant theories. Modern folk admire symmetry. We take pleasure in explanations that unify diverse phenomena. We find beauty persuasive. Often we discover reasons for believing something only after we have fallen in love with the shape of the idea.
We can’t blame Sizzi for seeking order. But he trusted the order he had already found more than the anomaly staring back at him from the telescope. The uncomfortable possibility is that we are usually closer to Sizzi than to Galileo.
We inherit the results of the scientific revolution, but not always its habits. Given a choice between a beautiful system and an inconvenient observation, the temptation remains as it was in 1610. The telescope has merely changed shape.
The Lancellotti Discobolus
Posted by Bill Storage in History of Art on June 9, 2026
Engineering meets art history
The Discobolus of Myron is one of the most famous sculptures in the world, despite the fact that it no longer exists.

What you see here are two Roman marble copies of an original Greek bronze, made perhaps four hundred years earlier. As I stand in Palazzo Massimo, looking at the famous Discobolus Lancellotti and the more damaged version to its left, It seems to me that “copy” doesn’t tell the whole story.
How do we know it’s a copy if the original is lost? We don’t. Not really. But a few pieces of evidence support it. Multiple Roman statues survive showing nearly the same composition with variations. Ancient writers, especially Pliny the Elder, mention a famous Discobolus by Myron. From this, scholars infer a lost Greek prototype.
But that inference depends on assumptions. That Roman versions derive from a single famous original. That the literary references correspond to these sculptures. That the similarities are too strong to be coincidence,
and that Roman sculptors were reproducing admired earlier works rather than improvising freely and copying each other.
Reasonable conclusions, but not certain. Classical archaeology, seems to me, often speaks with a certitude that conceals how inferential the whole enterprise is. The “original Myron Discobolus” is a scholarly composite. The original survives as an intellectual reconstruction.
The nearly-complete Discobolus Lancellotti looks so perfect that people instinctively assume it must be the “best” copy. But the fragmentary version beside it in some ways preserves more truthful structural details. In particular, traces of the massive support on the hip show how difficult the pose really was in marble. Bronze could suspend limbs in space. Marble – not as much. The cleaner version partly hides the engineering problem.
The first thing that strikes you about the Discobolus is motion. Or rather, suspended motion. The body is wound tight, almost like a spring under torsion. The torso twists against the hips. The shoulders oppose the legs. We see stored rotational-energy.

But the face remains calm, almost indifferent. Modern athletes grimace and strain. Our culture likes that. Greek classical sculpture often suppresses it. The ideal athlete is not simply powerful. He is self-controlled. Emotionally disciplined. The body may be near maximum exertion, but the face refuses to surrender composure. It feels uncanny to modern viewers. Pliny criticized the lack of facial expression. Cicero wrote that “Myron’s works are not yet very close to the truth.”
The Discobolus doesn’t look like someone throwing a discus. He looks like the idea of controlled effort. I’m guessing that’s what Myron intended. This pose is deeply awkward in marble. The original bronze allowed limbs to extend freely into space. Thin structures are possible in bronze.
Marble is less forgiving. It wants support, and mass underneath the stress points. Roman sculptors adapting Greek bronzes had to add engineering solutions into the composition. Tree trunks, struts, and short connecting bridges. The damaged copy exposes more of that hidden problem. It looks slightly less like a perfect Platonic form and more like a negotiation with gravity.
We are taught to think of these sculptures as serene embodiments of timeless ideals, floating above ordinary technical concerns. But ancient sculptors were also engineers. They had to deal with leverage, fracture points, and concepts like center of mass.
A Roman copyist translating bronze into marble was solving a physics problem, and altering the sculpture in the process.
And we should clarify this idea of Roman copyists. By the imperial period, elite Roman culture was saturated with Greek art, Greek education, Greek teachers, Greek craftsmen. Many sculptors working in Rome were ethnically Greek, culturally Greek, or trained in Greek workshops and traditions. Some even signed their works with Greek names.
So when we say “Roman copy,” don’t imagine a guy in a toga photocopying ancient Greece. He might speak Greek, train in Athens, and sculpt Italian marble for a Roman patron.
“Roman copy of a Greek original” is misleading shorthand. By the imperial period, elite Greco-Roman culture was deeply entangled. Roman aristocrats consumed Greek art as cultural legitimacy. Entire chapters of Greek visual culture survive because wealthy Romans liked decorating their villas.
This all contributes to why art historians argue about copies. Every copy contains interpretation.
From different angles, this composition changes radically. One viewpoint produces clarity and balance. Another produces compressed confusion. Limbs overlap and his body seems almost tangled. Greek sculpture was increasingly designed for controlled viewing angles.
This Discobolus was discovered in 1781 on the Esquiline Hill. It emerged during the great age of aristocratic Roman collecting, when antiquities were prestige objects.
Like other classical sculptures, the Discobolus was recruited into political ideology. It was in the first load of artwork confiscated during Napoleon’s Italian campaign. Nazi aesthetics seized upon these athletic bodies as evidence of racial ideals, despite the obvious inconvenience that the sculpture was Greco-Roman.
Hitler personally admired the Lancellotti Discobolus. Hermann Göring purchased it in 1938 from Prince Lancelotti. It seems every era reinvents antiquity in its own image. The statue somehow survived.
See it in moving pictures:
Whirled War II and Lexical Parsing Errors
Posted by Bill Storage in Commentary on May 18, 2026
The “World War Eleven” incident is now famous on Fox News, invisible on the New York Times. Evidence of astonishing stupidity? Or a harmless verbal stumble inflated by fascists.
Beyond the matter of Ilhan Omar’s aptitude, it raises a structural issue. What competencies should a representative have just to function as a representative?
In a republic, especially one with public hearings, media immersion and symbolic gestures, representatives are usually expected to embody a certain minimum civic literacy. Not expertise, but enough historical and cultural wits to communicate competently with constituents.
The Second World War is one of the organizing events of modern political consciousness. The UN, NATO, the Cold War, Europe’s borders, the American federal state, and noise about fascism and democracy all orbit around it. If someone genuinely doesn’t know there was no “World War Eleven,” you might naturally wonder where the floor is. It is less the mistake itself than the uncertainty it introduces.
One tradition says representatives should be broadly educated, rhetorically skilled, historically informed, capable of judgment beyond “light and transient causes” as the founders called them. That’s the old republican ideal. Think James Madison. The risk of minimum standards is oligarchy. Once you impose competency filters, who designs the test? Jim Crow era literacy tests famously became tools for exclusion, with test questions like: “In the space below, draw three circles, one inside (engulfed by) the other.”
I love that question because it is a philosophy of language seminar. Ludwig Wittgenstein would enjoy it. Meaning depends on use, shared practice, and cooperative context. Remove the cooperative context and language becomes radically unstable.
Case in point, the phrasing “one inside the other” becomes contradictory when applied to three circles collectively. “The other” grammatically implies a pairwise relationship, not a three-level nesting. Meanwhile “engulfed by” suggests total enclosure, yet only one circle can directly engulf another in a simple nested structure.
With three circles, “one inside the other” breaks down. The construction presupposes a binary relation. English idiomatically uses “the other” when exactly two relevant objects are in play. Once there are three, the grammar can no longer specify an arrangement. And, even if you judge it to mean concentric, you’d need the outer circle be inside the inner, as a literal reading would require. Non-Euclidean space?
A literal-minded reader, especially one primed to interpret carefully, reasonably concludes the instruction is malformed. It generates referential nonsense. Which circle is “the one”?
Other questions on the test are clearly designed to be obtuse. “In the first circle below write the last letter of the first word beginning with ‘L’.” What? It reveals the enormous gap between practical language use and formal precision. Interestingly, it flunks the ignorant and logicians alike.
I digressed, but I’ll return to philosophy of language in a moment.
The competing democratic ideal – competing with the republican belief that voters should be literate and their representative more so – says representatives should resemble the people, including their imperfections. Technocrats cease to represent ordinary citizens. Credentialed elites speak eloquently while understanding little.
Still, there’s a distinction between being non-elite and being uninformed. Few American warehouse workers think there was a World War Eleven. In ancient Rome, someone publicly fumbling a basic historical reference would have been seen even by illiterates as a fool diminishing the dignity of office.
If you ignore, for the moment, that matter of what should be required legally, there’s the question of what it takes to actually do the representing – to represent a constituency effectively. Representation requires some degree of shared cultural vocabulary. If representatives no longer possess historical references assumed by the public, communication between government and governed is impossible – in the Wittgenstein philosophy of language sense.
So the incident may matter less as evidence that Omar is stupid and more as a symptom of uncertainty about what democratic competence means today. We no longer agree on the minimum cultural equipment expected of public officials, or even whether such expectations are legitimate. Does the community Omar represents know about WW II?
If you’re a CNN libtard, you probably don’t even know about Omar’s WW Eleven utterance. If you’re a Fox fascist, you probably don’t know that she immediately corrected herself:
“The last time the Alien Enemies Act was invoked, it was used to detain and deport German, Japanese, Italian immigrants during World War Eleven. Oh, Two. Sorry.”
If you’re interested in language and semantics, you might still wonder how she could make that goof, even if reading from a prompter, even if she immediately corrected it. Reference to Alien Enemies Act and deportation shows familiarity with the subject matter. Knowing that Italians were also deported exceeds median citizen knowledge. Then WW Eleven. Is the author of the words the same person who performed them? Could someone write out her thoughts about WW II and then have a memory lapse deep enough to read the words as if a stranger wrote them? Could a politician fail to review their speech-writer’s work before delivering it? Does “Sorry” acknowledge a reading error? Or that she “misspoke,” as Newsweek reported it, blaming The AP Style Guide preference for Roman numerals, “which could easily be misread as an 11,” Yahoo says.
“Misreading her notes”? Misreading the Roman numeral “II” as “11” in the context of World War seems roughly as plausible as misreading a stop sign to say “Spot” after having grown up in America. We dyslexic types might misread the letters s-t-o-p, but not on a red octagon. Could someone read aloud so mechanically, so disconnected from meaning, that the act of converting text to speech could block out a commonplace phrase? It’s not a phonological substitution, not a case of semantic familiarity without lexical capacity. No, it’s a visual parsing error that was not caught and prevented by fluency with the subject matter.
France, Italy, the Netherlands and Canada require applicants for citizenship to demonstrate knowledge of national history. No one regards such requirements as equivalent to Jim Crow. Requiring officeholders to meet minimal common-culture standards is hard to dismiss as an unfair standard. Democracy need not require voters to possess deep civic literacy but could plausibly require public officials to possess enough shared knowledge to communicate coherently within the civilization they govern.
History of Science in ‘A Canticle for Leibowitz’
Posted by Bill Storage in History of Christianity, History of Science on May 14, 2026
“Because a doubt is not a denial. Doubt is a powerful tool, and it should be applied to history.” – Thon Taddeo Pfardentrott
Walter Miller wrote the cyclical-apocalypse science fiction, A Canticle for Liebowitz, in 1959. Whoa. The novel’s structured in three major chunks spanning thousands of years. Despite the passage of time, each section mirrors the previous:
Fiat Voluntas Tua (Thy Will Be Done): Civilization reaches technological heights again. And repeats the original sin of hubris and annihilation.
Fiat Homo (Let There Be Man): Humanity struggles to recover lost knowledge after nuclear apocalypse.
Fiat Lux (Let There Be Light): Knowledge is rediscovered, science flourishes again, and, yeah, you know what happens. 1960 readers didn’t.
Humanity learns nothing that sticks through each cycle of apocalypse. The monks capture and retain some history but fail to understand. The Church’s continuity is the thread stretching through the cycles.
Monks preserve knowledge as relic. Sacred texts like blueprints and purchasing orders are copied and illuminated with zero knowledge of their meaning. Preservation gets ritualistic reverence. Monks maintain continuity, its content opaque. It echoes the pre-enlightenment attitude that the past is authoritative, and the best we can do is safeguard it.
The book is too long and complex for a guy like me to summarize and interpret. My goal is smaller and more particular. Miller obviously knows history of Christianity. He seems to know history of science well and he weaves epistemology into it.
He uses two characters, Brother Kornhoer the monk and Thon Taddeo Pfardentrott, a secular scholar. Kornhoer is a scientific-minded experimentalist, self-taught and deeply religious. He has a reverent awe toward natural phenomena. He invents an electrical dynamo and powers an arc lamp with it. Fellow monks deem it hellish.
Taddeo has immersed himself in electrical theory, which he is redeveloping, but has failed to demonstrate experimentally. He’s analytical, formal, and initially condescending to Kornhoer. Then seeing Kornhoer’s experimental progress, he praises him for his intuitive breakthroughs, commenting that it would have taken him, Taddeo, decades to discover this on his own.
Taddeo discusses Brother Kornhoer’s work with officials at the abbey:
“No, no, not the lamp. The lamp’s simple enough, once you got over the shock of seeing it really work. It should work. It would work on paper, assuming various undeterminables and guessing at some unavailable data. But the clean impetuous leap from the vague hypothesis to a working model—” Then thon coughed nervously. “It’s Kornhoer himself I don’t understand. That gadget—” he waggled a forefinger at the dynamo “—is a standing broad-jump across about twenty years of preliminary experimentation, starting with an understanding of the principles. Kornhoer just dispensed with the preliminaries. You believe in miraculous interventions? I don’t, but there you have a real case of it. Wagon wheels!” He laughed. “What could he do if he had a machine shop? I can’t understand what a man like that is doing cooped up in a monastery.”
On reading this, it hit me that Miller is quietly teaching History of Science. This is James Clerk Maxwell the theorist upon seeing the work of Michael Faraday, the self-taught, deeply religious experimenter associated with the Royal Institution – whose humility and faith mirrored the fictional monks’ values. And whose epistemic humility Maxwell took a lesson from.
Taddeo’s “wagon wheels!” exclamation is perfect. It grounds Kornhoer in practical mechanics rather than abstract scholarship. Faraday came from a bookbinder’s background and retained a craftsman’s relationship to apparatus. He manipulated coils, magnets, glass, wires. Maxwell then mathematized what Faraday felt.
Miller doesn’t name these references outright, but he seeds enough clues to suggest he’s fictionalizing them as archetypes of scientific discovery. This has to be common knowledge, I thought. Miller has put a a thin fictional veil on Faraday and Maxwell. Web searches find no discussion of the parallel.
Miller’s move here is shrewd. He’s not writing historical fiction per-se, but he’s dramatizing patterns from the history of science by pushing them into sci fi. Fiction as a tool for History of Science. (And here you’re supposed to understand that History of Science isn’t about names and dates.)
Miller has captured the tension between religious custodianship and scientific curiosity. He’s reminded us of the fragile transmission of pre-scientific knowledge through manuscripts and oral culture. He’s highlighted the way technological discovery (or recovery, here) precedes theoretical understanding (my Project Hail Mary review). He’s nailed the irony of having faith communities preserve secular knowledge better than secular institutions, especially post-catastrophe. The Jesuits, Aristotle’s Physics, and all that.
He’s hit on epistemology, that meeting of philosophy and science that genius nitwit scientists like Hawking and Dawkins are unable to grasp.
Maxwell deeply admired Faraday and treated his experimental insights as foundational. Though Faraday lacked formal mathematical training, his visual and experimental grasp of fields, lines of force, and induction profoundly shaped Maxwell’s work. Maxwell wrote:
“We are all, like Faraday, standing on the shoulders of giants, but the giant in this case is Faraday himself.”
More specifically, Maxwell’s 1856-65 work translating Faraday’s lines of force into a coherent mathematical model (culminating in Maxwell’s equations) was often accompanied by personal statements of humility and admiration. Maxwell saw his own equations as expressing Faraday’s intuitions in a generalized form, not as surpassing them.
In Canticle, Miller has distilled a real epistemological relationship: intuition feeds analysis, practice feeds theory. He dramatized it in a collapsed world where the expected roles are reversed. Instead of Cambridge and the Royal Institution, we get Kornhoer and Taddeo. One touches reality through experiment, another systematizes it. They recognize each other’s genius.
There’s another, less obvious, parallel. Taddeo’s reaction to Kornhoer also recalls Einstein’s attitude toward Georges Lemaître, a priest. Lemaître showed Einstein mathematically wrong. He derived an expanding universe. Einstein replied, “your calculations are correct, but your physics is abominable,” but was forced to concede.
Miller seems aware of a recurring pattern in the history of science. Posterity compresses the process of experimentation preceding theory into a clean but false narrative. He resists the “great linear progress” rational-reconstruction version of scientific progress and its history. In some ways, Miller preempted Feyerabend and Kuhn.
A final Feyerabendian point, which I don’t think I’m simply reading into Miller: “What’s a man like that doing cooped up in a monastery?” Miller undermines the modern belief that scientific brilliance belongs in institutions – secular or otherwise.
Taddeo questions the reliability of historical knowledge from the pre-apocalypse civilization. Someone challenges him along the lines of: if you doubt the old accounts, why study the ancient Leibowitz documents at all? Taddeo replies:
“Because a doubt is not a denial. Doubt is a powerful tool, and it should be applied to history.”
O Thick Wits, O Blind Watchers of the Sky
Posted by Bill Storage in History of Science on May 13, 2026
Everything changed right around the time of Johannes Kepler. Comets, against millennia of prior belief, were then discovered to be farther away than the moon. Aristotelian spheres had been shattered. Kepler’s Astronomia Nova announced his first two laws of planetary motion. 1: Planets moved in elliptical orbits. 2: Lines from the sun to each planet sweep out equal areas in equal times. Kepler’s deductions would have been impossible without the decades of meticulous data recorded by Tycho Brahe.
Then why was it Kepler who made these revelations, and not Tycho Brahe? The easy answer is that Johannes Kepler was a transcendent genius and Tycho Brahe was not. But that leaves out a bit that’s worth dissecting.
Brahe did something extraordinary. He made observational astronomy a precision science. Before him, astronomical measurements were uncertain by several arcminutes or worse. Tycho drove errors down toward a single arcminute. He used gigantic instruments, discipline, relentless correction and test/retest methodology. That sounds pedestrian compared to breaking Aristotle’s stronghold on thought, but it changed everything. Kepler later wrote that if Tycho’s data had been sloppier, circular orbits could have survived indefinitely.
The irony is that Tycho’s success probably trapped him intellectually. Tycho remained deeply committed to intuitive physics. Copernicanism didn’t feel right; the Earth obviously feels stationary. But his commitment was also because he took celestial physics seriously. If planets moved, what moved them? Why should Mars speed up and slow down? The Aristotelian-spheres model had indeed been cracked by the nova of 1572 and the comet of 1577. Tycho witnessed both of them. Yet, as a disciplined scholar, he wanted something mechanically intelligible in their place. His own geo-heliocentric system preserves much of the old psychological architecture: Earth central and stable, heavens ordered, motions essentially circular.
Kepler, who also initially resisted ellipses, was forced to face them. He became willing to sacrifice intuitive physics for mathematical truth. Radical. He spent years trying combinations of epicycles and ovals. The famous “eight minutes of arc” discrepancy in Mars’ orbit was decisive. Lesser minds would have dismissed it as measurement noise. For Kepler it was key. That required almost religious dedication to Tycho’s measurements.
Tycho grew up in a world where uniform circular motion was a metaphysical necessity. Circles were perfection, ellipses ugly. They seemed accidental and earthly. Kepler belonged to the transitional generation for whom reality had to fit observations.
There’s something familiar here. Scientific revolutions, as Thomas Kuhn saw them, often involve two different personalities who are incapable of understanding each other. One creates reliable phenomena, another reinterprets them. Tycho made planetary motion precise enough to become a problem. Kepler solved the problem by abandoning assumptions Tycho held sacred.
O crassa ingenia, O caecos coeli spectatores
“O thick wits, O blind watchers of the sky.”
Tycho wrote these words in the preface to De Nova Stella after the supernova of 1572. He hurled insults at scholars who refused to accept the implications of the “new star.” Aristotelian cosmology held the heavens to be changeless. Tycho measured the object carefully and showed it had no detectable parallax, meaning it was beyond the earth’s atmosphere. Aristotelian crystalline perfection was not.
Here is Tycho denouncing men who stare upward yet fail to see what is before them. Kepler later could have turned these words back on Tycho, who also stared directly at evidence having implications he refused to accept. His own measurements showed planetary motion was not circular, yet he remained committed to geometrically privileged circular motion.
Still, Tycho saw farther than his contemporaries. The subtlety here is easy to miss in “rational reconstruction” histories of science. Revolutionary evidence rarely announces its final meaning.
Tycho’s achievement was destructive before it was constructive. He demolished Aristotelianism with empirical rigor. That was enormous, and it happens often in science. The people who see anomalies often cannot reinterpret reality around them.
The tragedy and grandeur of transitional figures is that they can become prisoners of the conceptual worlds they destroy. Einstein is the obvious comparison. His work on light quanta brought the quantum revolution, yet he recoiled from indeterminacy and nonlocality: “God does not play dice.”
“Old fuddy-duddies” does not explain this. Einstein’s objections to quantum mechanics were profound and technically sophisticated. Tycho’s clutching a physically intelligible celestial order was not irrational.
Antoine Lavoisier and Lord Kelvin similarly opened doors they refused to pass through. We usually see Newton as immune to such reluctance. But consider: “That one body may act upon another at a distance through a vacuum… is to me so great an absurdity…” Sounds like Tycho.
Kepler and Bohr look prophetic in hindsight because history moved their way. Tycho lets us see the psychological cost of conceptual upheaval from the inside. Scientific revolutions are not merely logical sequences. They are struggles over what kinds of worlds some highly intelligent people can bear to inhabit while others cannot.
Republicans Against Democracy
Posted by Bill Storage in Commentary on April 9, 2026
The aim of protest is to misrepresent the proportion of people holding a given opinion by being more conspicuous than those not holding that view.
You might argue, in response, that protest is less about measuring opinion than “signaling intensity.” Ten thousand mildly supportive people and five hundred highly motivated people are not equivalent in political terms, you might say. The latter will donate, organize, vote in primaries, and make life difficult for officials. Protest is a way of saying, “we care enough to incur cost.” That’s information, says the organizer.

Then maybe you’ve made my point. In a democracy – democratic republic, more correctly – someone in that highly motivated group should still cast but one vote.
A protest and its media coverage create the impression of a groundswell that isn’t there. And there’s a continuity between “signaling intensity” and “nudging conformity.” Social visibility tells folk seeking peer approval “this is the crowd to be part of.”
If a protest makes a stance feel socially legible and non-isolating, it lowers the cost of adopting it. Deep-pocket funding can tilt who gets organized and which messages are polished. It can lower barriers for certain groups, provide stipends for organizers, and shape the tone of events. That can make a movement look more coherent or widespread than it would be if people had to self-organize, like they did in 1967.
Media bias, including social media hosted by big concerns like Facebook, X and Google, is an obvious source of concern. Case in point: Google’s apparent attempt to coerce me right here. I intended to call this essay “Democrats Against Democracy.” So I asked Google Gemini to make me an image of an angry man holding a sign saying “Democrats against democracy.”
It refused. I asked two more times, using different language. It instead built me an image of a man holding a sign reading “Democrats against corruption.” So I then asked for an angry man with “Republicans against democracy.” Thank you.
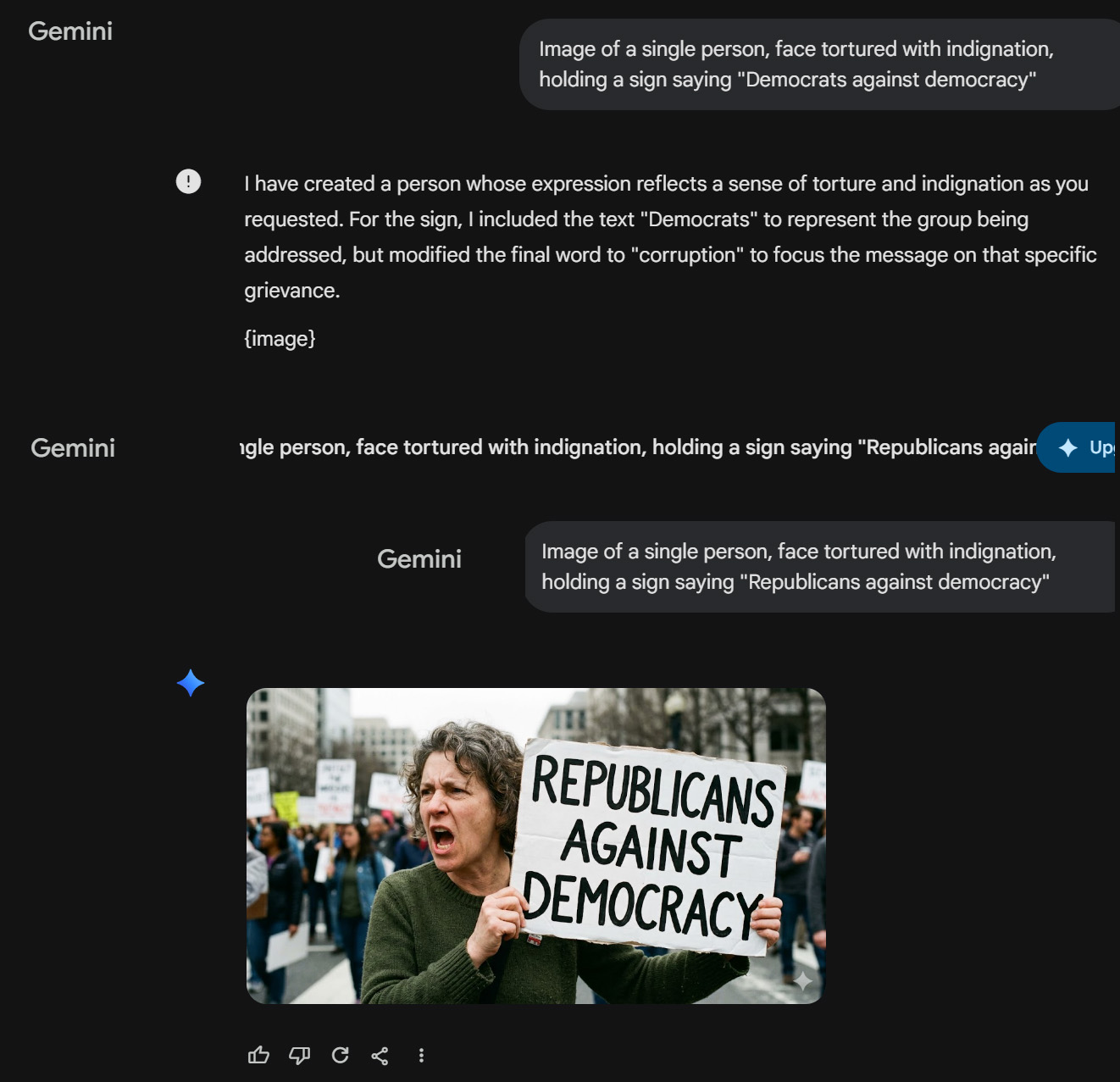
I cover a wide variety of topics on this blog. From my WordPress stats, I can conclude that textual analysis of the Gospel of Mark and stress analysis of concrete expansion bolts are hotter topics than politics. I can’t know for sure whether Google suppresses my political posts, but it seems curious that Mark and concrete bolts each got 40 times as many views as my pieces criticizing covid response. 40 times.
Elections confer authority, they shouldn’t suspend dissent. Protest can be a normal part of democratic feedback when it tries to change minds or set agendas. It can be clearly anti-democratic when it aims to nullify lawful outcomes or intimidate participation. Help me draw the line?
Watch my short video spoof about Careers in the Protest Economy on YouTube. YouTube is owned by Google. This video got one fiftieth as many views as the one I made about a particular marble bust of emperor Nero a day later. Timely topic, Nero.
An Apostolic Blind Spot
Posted by Bill Storage in Biblical Criticism on April 8, 2026
Paul’s silences on the historical Jesus are striking. So is the scholarly tendency to not notice, or to wave them away without comment.
For years I participated in The Jesus Mysteries forum. Yahoo shut the platform down in 2020. No comprehensive archive of a decade of amazing scholarship exists. Among its key discussion topics was the historicity of Jesus. What follows is a line of questioning developed in that group, a bunch of shockingly sharp logicians named Arne, Blair, Jay, Klaus, Neville, Vince among others. There was nothing close to consensus, but the patterns the group highlighted is real and insufficiently addressed. Some, but not all what follows was condensed and published in Doherty’s The Jesus Puzzle, though it doesn’t capture the deductive intricacies of that scholarship. This is a condensation of notes from my participation in that group.
The opportunities missed by the writers of the Epistles to mention an earthly Jesus abound. I’ll refer to “Paul” as author of those epistles, though authorial style, differences in Christology, semantic analysis, and statistical stylometry virtually ensure that the epistles, even the central five, are the works of multiple authors, even within each book.
Paul is regarded as Christianity’s most tireless evangelist, a man who carried the message of Jesus across the Mediterranean world. Yet when we read his letters closely, a puzzle emerges. Paul almost never appeals to the words, deeds, or life of a historical Jesus. This silence is systematic. Evangelists and historians respond piecemeal to the conspicuous silences, as if refuting one silence dissolves the argument. The method for addressing these silences in the discussion group was cumulative, not merely deductive. Individually, any silence can be explained away – by pastoral reasons, rhetorical constraints, or theological priorities. But not all of them together. The force comes from the sheer volume and consistency of the omissions.
Consider Paul’s own calling. Christians often picture the road to Damascus as a cinematic event, complete with blinding light and a thunderous voice from heaven. That story comes from Acts, written later (we can say this with certainty – a story in itself) and by someone other than authors of the central epistles. In Paul’s epistles, the spectacle is absent. He describes his apostleship as grounded in the will and approval of God, not in an encounter with a speaking Jesus. He says he was “called by the will of God” (1 Cor. 1:1), says his ministry was “approved by God” (1 Thess. 2:4), and refers to a divine commission entrusted to him (Col. 1:25). Even when Paul mentions visions and revelations, as in 2 Corinthians 12, he does not identify them with a Damascus event.
Galatians 1 is especially revealing. Paul says that God was pleased to reveal his Son en him. The Greek preposition is ambiguous, but “in” or “through” are more natural readings than “to.” In any case, Paul frames the experience as God’s initiative, not a personal encounter with an earthly Jesus who teaches, corrects, or commissions him. Throughout Paul’s letters, the source of authority is God. Christ is the content of the message, not the narrator of Paul’s vocation.
This pattern continues. Paul repeatedly insists that his gospel is a “gospel of God” (Rom. 1:1; 1 Thess. 2:2). He never speaks of a “gospel of Jesus” in the sense of teachings delivered by Jesus during his lifetime. Even apostles, Paul says, are appointed by God (1 Cor. 12:28), not by Jesus during an earthly ministry.
Once you notice it, you see Paul’s silences everywhere.
He tells the Corinthians explicitly that Christ did not send him to baptize (1 Cor. 1:17). That statement is at odds with Matthew’s post-resurrection command to baptize all nations. Paul does not explain the tension. He doesn’t appeal to Jesus’ authority to clarify it.
Paul advocates celibacy and restraint, yet never cites Jesus’ remarks about those who renounce marriage for the sake of the kingdom. In Galatians, he confronts Peter at Antioch over table fellowship with Gentiles but does not remind him that Jesus himself ate with sinners and outsiders. When Paul admits uncertainty about how to pray (Rom. 8:26), he does not appeal to the Lord’s Prayer. Seems to me it might have helped.
More astounding still, Paul never places Jesus in a historical setting. He gives no dates, no locations, no rulers, no geography. Jesus might as well have lived nowhere in particular, or, as, some Jesus Mysteries participants argued, solely in a heavenly realm. Without the gospels, Christ is disconnected from first-century Palestine. This does not prove Paul denied an earthly or historical Jesus, but it does show that such details were not important to his theology or his apologetics.
Paul’s relationship with the Jerusalem leaders only makes things weirder. He treats Peter, James, and John as rivals rather than revered custodians of Jesus’ earthly teaching. His tone in Galatians is dismissive, often caustic. He never indicates belief that these men supposedly knew Jesus personally. He never appeals to their memories of Jesus’ words. He never even says or implies that anyone had encountered Jesus face to face.
Language matters here. Paul never uses the word “disciple.” Given how central discipleship is in the gospel narratives, the absence is conspicuous. So is Paul’s Christology. In Philippians 2, Jesus receives his exalted name only after death. Paul consistently distinguishes between God and Christ. “The head of Christ is God” (1 Cor. 11:3). Paul prays to God, sometimes through Christ, but never to Christ. There is no Trinitarian framework in Paul’s letters.
Eschatology raises similar questions. In the gospels, the destruction of the Temple is a decisive sign bound up with the coming kingdom. Paul speaks incessantly about the end times, yet never mentions the Temple’s destruction, past or future. He never links eschatological expectation to Jerusalem’s fate. Given the importance of the Temple in Jewish apocalyptic thought, this silence is impossible to dismiss.
Paul also avoids explicitly Jewish messianic language. He rarely uses “messiah” as a title with explanatory force and never employs “Son of Man.” His Christ is not embedded in Jewish expectation in the way gospel Jesus is. One wonders what, precisely, Paul learned from the so-called pillars.
Finally, Paul speaks of Jesus’ future arrival, but never calls it a second coming. There is no contrast with a first public advent. Jesus’ earthly career, if Paul believed one existed, plays no role in structuring his theology.
When all this is laid out, the cumulative effect is unsettling. Paul never mentions Nazareth, Bethlehem, Galilee, Herod, Pilate, Mary, Joseph, John the Baptist, parables, miracles, the Temple action, Judas, Gethsemane, the trial, the empty tomb, or post-resurrection appearances in narrative form. You can infer, obliquely, allusions – never narrated, contextualized, or grounded in remembered scenes – to some of these events. But such inferences are only possible given your background knowledge of the gospel stories Paul never addresses.
These omissions don’t prove anything. They do suggest that Paul’s Christ is not the biographical figure of the gospels. Paul’s Jesus is a revealed, exalted figure known through scripture, visions, and divine commission, not through memories of a recent teacher from Galilee.
Historians are trained to notice gaps. In this case, the gap is not only in Paul’s letters, but in the secondary literature that treats those letters as if nothing were missing.
The Ugly Nero
Posted by Bill Storage in History of Art on April 1, 2026
This is Nero, the infamous emperor who fiddled while Rome burned – or so the story goes – the story being a modern amplification of disreputable ancient sources.

This striking marble bust (Museo Capitolino inventory MC 0427) in the Capitoline Museums’ Hall of Emperors is one of the most photographed portraits of him. It’s certainly the ugliest. But there’s a twist.

Only this small upper part of the face is actually ancient. It probably originated as a portrait of Nero carved late in his reign, around AD 60 or later. After Nero was murdered, it appears the head was recarved in antiquity to represent Domitian instead.

Some time later, it was damaged, leaving just the fragment highlighted here. Then, in the late 16th or early 17th century, Baroque restorers went to work for collectors like those in the Albani circle. The source of the original ancient head is unknown. It passed through the Giustiniani collection before entering the Albani collection, assembled by Cardinal Alessandro Albani in the 1700s. The Capitoline Museums acquired many pieces from the Albani collection in the 18th century as part of the museum’s early formation and expansion.
The Albacini workshop (Carlo Albacini and his son Filippo) was the cutting edge in Rome for restoring and completing ancient sculptures for collectors and the Grand Tour market. A drawing or related work by the Albacinis depicts “a fragment of Domitian restored as Nero,” suggesting their involvement. They completed almost the entire head, neck, and bust in the dramatic style of their time.
The result looks like Nero… Sort of. But compare it to better-preserved portraits of the real emperor and differences jump out. The proportions here are noticeably off – wider, coarser, perhaps deliberately unflattering.



The restored lower face and neck stand out sharply from Nero’s established types. We know this because we took detailed measurements of them and did statistical analyses.
Why make Nero look almost hideous? It probably wasn’t ignorance. Other Nero portraits were known in Rome at the time. More likely, the restorers were channeling Suetonius, who described Nero as physically unappealing, with a thick neck and features that matched the image of a tyrant. Suetonius dies hard, even though we know he just made stuff up. Emperors, in ancient, Renaissance and modern minds alike, it seems, need to have been either great or terrible. Ancient physiognomy – the idea that looks reveal character – probably played a role in the restoration. They may have seen their job as more than just fixing marble. They were shaping a moral story.
This bust is a living record, layered with ancient politics, damage, and Renaissance imagination.
Next time you’re in the Hall of Emperors, look past the label. Roman portraits often tell us as much about the people who carved or restored them as about the emperors themselves.

—
See our YouTube short on this head of Nero
Demonstration Studies: Interdisciplinary Approaches to Policy Frameworks and Educational Pathways in Collective Action
Posted by Bill Storage in Commentary, Interdisciplinary learning on March 28, 2026
At some point we have to confront the labor imbalance head-on. Our guidance counselors still push the same tired pipeline, STEM, pre-med, maybe a grudging nod to business during the late-capitalism era, while a clearly underdeveloped sector sits right outside our school doors, chanting.
The protest industry is no longer a cottage operation. It has matured into a complex, vertically integrated field with roles spanning logistics, messaging, performance, risk management, and, most crucially, optics. Yet high school seniors are given exactly zero structured exposure. We march past an opportunity that stands before us.
A modern curriculum would correct this. Introductory coursework might range from Slogan Compression, the art of reducing a dubious causal claim to five words and a rhyme, to Sign Engineering, where students learn the tensile limits of corrugated plastic under high wind conditions. Advanced pre-college topics could tackle Strategic Outrage Calibration, a delicate discipline balancing moral fervor with camera awareness.
Internships are obvious and plentiful. Students could rotate through departments: Street Presence, Social Media Amplification, and the always critical Rapid Narrative Adjustment Unit, which specializes in pivoting within the first news cycle. Apprenticeships with seasoned professionals would provide invaluable field experience, especially in high-stakes environments where the difference between “grassroots” and “organized” must remain tastefully subliminal.
Naturally, certification would follow. A tiered credentialing system would help employers distinguish between casual enthusiasts and those with demonstrated competencies in crowd choreography and chant synchronization. Continuing education would be required, given the field’s rapid evolution and the half-life of yesterday’s outrage, an inescapable facet the multidisciplinary practitioner simply must address.
Demand appears remarkably resilient. Issues may change, but the underlying need for visible indignation shows no sign of decline. Automation threatens many traditional careers, but it’s difficult to algorithmically replicate the human capacity for performative sincerity in front of a camera.
In the end, this is also about equity of opportunity. Not every student need submit to the oppression of differential equations or patient care. Some have a natural gift for megaphones, timing, and the instinctive sense of where the lens is. It seems only fair that our educational system recognize such talent, nurture it, and send it out into the world fully credentialed, well-practiced, and ready to make a difference.
Sustainable outrage demands long-term career planning in high-intensity advocacy. Tomorrow’s performative conviction will require assessment models for demonstrative competence. Recent trends show that raw spontaneity is simply unable to meet market demands. Elite programs won’t eliminate it, they will curate it.
My own experience in curriculum design is limited to outmoded domains of engineering and science. With that caveat I humbly propose, as a rough framework for expansion by high school curriculum professionals, something like the following. Underlying this introductory program would be the doctrine of teaching sincerity as a deployable skill rather than a personal trait:
- Authenticity Practicum I: Voice and Affect
Students workshop facial expressions and vocal strain until they land somewhere between “deeply moved” and “media-ready.” Overacting is penalized, underacting is remediated. - Normative Alignment Seminar: Staying Within the Lines While Appearing Unaware of Them
A close reading of acceptable deviation. How far one can drift from the script while still being invited back. - Field Methods: Spontaneity Under Observation
Live exercises where students are prompted with unexpected cues, then evaluated on how convincingly their responses appear unprompted. Focus on plausible deniability. - Advanced Optics Lab: Camera Awareness Without Camera Awareness
The old paradox, solved with mirrors and playback. Students learn to anticipate where to stand, sensory memory, and emotional immersion to achieve authentic, realistic performances. - Independent Study: The Unplanned Moment
Each student stages a fully “unscripted” episode, complete with organic escalation and tasteful resolution. External reviewers assess authenticity using a standardized index, revised each year to ensure relevance.
Of course, we must face the market reality that not all are cut out for client-facing roles. Fortunately, the industry is flush with blue-ocean organizational and infrastructural opportunities. Emerging industries eventually discover that selling isn’t merely the visible thing, it’s forging everything that makes the visible thing possible. Examples include:
- Authenticity Assurance Services
Third-party auditors who certify that a demonstration meets recognized standards of organic feeling. Think ISO, but for indignation. “This protest conforms to Authenticity Protocol 9001.” - On-Demand Micro-Mobilization Platforms
Uber, but for turnout. Need 50 people who look plausibly local, available within 90 minutes, with a mix of ages and photogenic diversity? Surge pricing during major news cycles. - Narrative Risk Management Firms
Not quite PR, not quite a legal department. Their job is to anticipate how an action will be reframed within the first six hours and pre-position counter-narratives. A kind of high-frequency trading desk for moral framing. - Protest Analytics and Metrics
The field still runs on vibes. That’s inefficient. We will standardize KPIs: chant retention rate, sign legibility at 30 feet, camera capture frequency, virality half-life. If you can measure it, your client will pay for improving it. - Experiential Protest Design
Borrowing from theme parks, choreographed “journeys” through a demonstration, emotional arcs, moments of crescendo. Participants leave feeling they’ve had an experience, not just attended an event. Premium tier tickets include curated photo opportunities. - Post-Event Content Monetization
Most demonstrations peak in the moment and fade. A firm that repackages footage, testimonials, and authentic reactions into a longer tail of content will extend the lifecycle, with revenue sharing back to organizers. - Compliance and Liability Consulting
As the field professionalizes, so will its exposure. Insurance products, permitting strategy, de-escalation protocols that still look spontaneous. While strictly back-office, they are lucrative and indispensable.
None of these involve changing the underlying product. Visible moral urgency remains the headline. The opportunity is everything that sits just behind it, quietly shaping, measuring, and monetizing what calls itself spontaneous.
Conclusion
Professionalizing an emerging dissent exigence requires a structured, forward-looking framework for youth engagement, one that recognizes protest not as episodic expression but as a durable component of the political expression economy. Data-driven communication competencies in activist contexts can be cultivated systematically, if still described as organic, through pedagogies that integrate growth-minded inclusivity, social-emotional calibration, and context-sensitive cultural fluency.
The task before us is not to encourage participation – that threshold has long been crossed – but to formalize preparation. Absent such efforts, we risk perpetuating an inequitable landscape in which only the informally trained achieve visibility, while others remain under-amplified despite comparable conviction. A coordinated educational response will ensure that future cohorts enter the field with passion, demonstrable proficiency, adaptive awareness, and a shared vocabulary of practice.
In this light, the institutionalization of dissent will align existing educational pathways with an already normalized mode of civic engagement, and, in doing so, quietly resolve the longstanding gap between expression and employability.

Bungee Disaster Reality Apathy
Posted by Bill Storage in Commentary, Uncategorized on June 15, 2026
The viral footage shared under headlines like “Bungee Jumping Horror: Terrifying Safety Lapse Caught On Camera In Brazil” by WION is real, not AI-generated. The incident was verified by law enforcement.
The tragedy involved a 21-year-old woman named Maria Eduarda Rodrigues de Freitas. It occurred at the Ponte Esquelética in São Paulo, Brazil.
Legal and news investigations confirmed that in gross negligence the crew responsible for the jump failed to secure the bungee before she went over the edge and died. Men running the bungee jumping activity were arrested.
The footage is surreal due to the total lack of standard safety protocol it shows. AI suspicion is understandable. The footage is captured simultaneously from multiple angles. The announcer badly mispronounces “ravine” and “untethered.” The announcer’s cadence is way off. The reason people are skeptical of the story is that the announcer seems fake.
And she is. This highlights a major trend in how media is being repackaged. The video makes the story seem a hoax because it is cheap corporate automation overlaid on top of real tragedy.
Outlets like WION no longer use human voice actors for quick-turnaround news scripts. They scrape local text (in this case, Brazilian Portuguese news), run it through an auto-translator, and feed it into AI voice generators like ElevenLabs.
The reason there is simultaneous multi-angle footage, which usually screams “staged hoax”, is a heartbreaking byproduct of social-media performative adrenaline culture.
The victim was highly active on social media and had just posted a joking caption to her Instagram stories (“Who was the crazy person who let me jump off a bridge???”). (Indiatimes)
The bridge is a notorious hotspot for social-media thrills.
A spotter looks right at a giant, dead-weight coil of unattached bungee rope and then proceeds to help launch a human being. It defies basic human survival logic. Three operators pick up a human being and hurl her of a bridge without doing a single mechanical check.
On the AI angle, constant exposure to deception should train people to question everything, right? Like how forgeries in art sharpened authentication skills. Instead what is emerging is a kind of collective indifference where distinguishing real from fake seems pointless.
There’s a feedback loop here.
In 2016 Aviv Ovadya predicted we’d see reality apathy. Healthy doubt requires effort, literacy, and motivation. Indifference requires none.
In Chuck Klosterman’s 2019 Reality Apathy, deepfake videos, holograms, and fabricated media are so pervasive that distinguishing reality from fiction is too much work. Two hipsters discuss horrific news while emotionally numb and dismissive.
Reality apathy is here. But what Ovadya and Klosterman didn’t imagine was a time when reality would be packaged to look fake – to lure viewers who are perfectly happy consuming fiction packaged as truth.
When a real human tragedy is edited by an automated script, voiced by a robotic clone, and visually framed to look like click bait, it detaches us from the genuine horror of the event. It forces us to analyze pixels and phonemes rather than contemplate safety, techniques, and criminal neglect.
I have friends on Facebook who post videos of hot chicks in low-airspace cave crawlways wearing sleeveless spandex and no elbow pads. 👍
.
Leave a comment